
Kontrollvariablen – Kovariaten – Störvariablen
Kontrollvariablen – oder auch Kovariaten oder Störvariablen genannt – sind Variablen, die zusätzlich als Prädiktoren (unabhängige Variablen) in ein statistisches Modell mit aufgenommen werden. Dies wird gemacht, um
- deren Effekt „heraus zu rechnen“ bzw.
- für deren Effekt zu kontrollieren bzw.
- deren Effekt zu neutralisieren.
Als Resultat sind die Effekte der anderen Prädiktoren im Modell dann für diese Kontrollvariable(n) kontrolliert.
Kontrollvariablen sind oft metrisch, können aber auch kategorial sein. Meist interessiert der Effekt der Kontrollvariable auf die abhängige Variable selbst inhaltlich nicht. Trotzdem kann man ihn im Modell mit ablesen, denn statistisch wird die Kontrollvariable wie ein Prädiktor verwendet und somit bekommst Du auch ein Ergebnis (z.B. Regressionskoeffizient und p-Wert) für den Effekt der Kontrollvariable auf die AV.
Beispiel für die Verwendung in einer linearen Regression
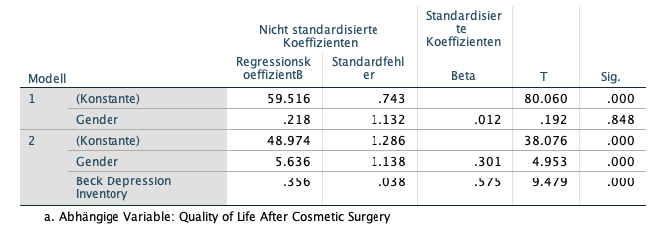
In diesem Beispiel zeigt sich, was oft mit der Verwendung von Kontrollvariablen erreicht werden soll.
Es wurden hier zwei Regressionsmodelle gerechnet, jeweils mit der Variable Lebensqualität als abhängige Variable (lineare Regression). Im ersten Modell wurde nur der Einfluss von Geschlecht (Gender) untersucht, der dort nicht signifikant war (p = .848). Im zweiten Modell wird zusätzlich zu Geschlecht auch der Parameter Depression mit als Prädiktor aufgenommen. In diesem zweiten Modell ist nun Geschlecht signifikant (p <.001). Das heißt, wenn für die Depression kontrolliert wird, ist ein signifikanter Effekt vom Geschlecht auf die Lebensqualität nachweisbar. Daneben wird im zweiten Modell auch ersichtlich, dass die Depression einen signifikanten Effekt hat. Allerdings wäre das hier in diesem Beispiel nicht Teil der Hypothese und würde nur als Nebenergebnis berichtet werden.
Du willst mehr verständliche Erklärungen und endlich Durchblick im Statistik-Dschungel?
Verwendung von Kontrollvariablen in verschiedenen statistischen Modellen
Im obigen Beispiel wurde ein lineares Regressionsmodell verwendet. Kontrollvariablen kannst Du aber in vielen weiteren statistischen Methoden einsetzen. Welche Methode jeweils passt, hängt fast immer vom Messniveau der abhängigen Variablen und vom Studiendesign ab. Grundsätzlich ist es aber in allen komplexeren Modellen möglich, mit Kontrollvariablen zu arbeiten, z.B.
- in der ANOVA, sie wird damit dann zur ANCOVA (Kovarianzanalyse),
(hier klicken für einen Blogartikel zur ANCOVA) - in der Messwiederholungs-ANOVA,
- in der gemischten ANOVA,
- in der logistischen, linearen oder ordinalen Regression und
- in Multi-Level-Modellen.
Für viele dieser Methoden findest Du ausführliche und verständliche Anleitungen in der Statistik-Akademie. Hier lernst Du im Detail, wie die Methoden eingesetzt werden, was die Voraussetzungen sind und wie Du sie in SPSS, R oder DATAtab umsetzen kannst. Auch zum Thema Kontrollvariablen gibt es dort noch ausführlichere Inhalte von mir. Zum Beispiel gehen wir dort auf das Thema ein, wie Du Deine Kontrollvariablen am besten auswählst.
Quellenangabe verwendeter Datensatz für das Beispiel: Andy Field, Discovering Statistics Using SPSS, SAGE, 4. Auflage.
Die 10 häufigsten Fehler bei Abschlussarbeiten mit SPSS und wie du sie vermeidest.
Hol dir jetzt die Liste für 0,- Euro und komm mit deiner Datenanalyse fehlerfrei und schnell voran!

Ich bin Statistik-Expertin aus Leidenschaft und bringe Dir auf leicht verständliche Weise und anwendungsorientiert die statistische Datenanalyse bei. Mit meinen praxisrelevanten Inhalten und hilfreichen Tipps wirst Du statistisch kompetenter und bringst Dein Projekt einen großen Schritt voran.





Hallo Daniela,
ich möchte den Zusammenhang zwischen körperlicher Aktivität (UV1) sowie Sitzzeit (UV2) mit Rückenschmerzen (AV1) und mit Gesundheit (AV2) untersuchen.
Klassische Confounder wären: Alter, Geschlecht, Bildung, Einkommen, Migrationshintergrund, Ost/West. Diese würde ich in die beiden Regressionen (zwei Regression, weil 2 AVs) aufnehmen.
Es gibt aber auch noch viele weitere Einflussfaktoren, welche im Zusammenhang mit der UV und AV stehen, zum Teil aber auch auf dem Pfad zwischen UV und AV liegen könnten, wie z.B. Body-Mass-Index usw. Kann ich diese Kovariaten ebenfalls in die zwei Regressionsmodelle einfach aufnehmen, sodass ich insgesamt zwei große Regression habe ? In diesen beiden Regressionen würde ich dann auch die UVs gegenseitig adjustieren, hätte Confounder, potenzielle Mediatoren usw., also kurz gesagt alle möglichen Kovariaten reingeworfen. Bei dem Vorgehen könnte es zur Überadjustierung kommen.
Ich hätte deshalb pro UV zusätzlich eine eigene Regression gerechnet, wo der totale Effekte sichtbar wird, dabei würde ich nur strenge Confounder (Alter, Geschlecht, Bildung, usw., welche zeitlich vor der Exposition liegen) einbeziehen, um das Problem der Überadjustierung einzudämmen. Ich hätte dann aber auch 6 Regressionen, was die Auswertung umfangreicher macht.
Ist der Weg mit den 6 Regressionen methodisch sauberer und ist er überhaupt interessant, weil man ja viele interessante Kovariaten weglässt?
Vielen Dank schon mal. Viele Grüße
Hallo Ju,
ja, so kannst du vorgehen. Alternativ könntest du auch erstmal mit allen bivariaten Korrelationen starten und anhand derer auswählen, ob eine Kovariate mit aufgenommen wird oder nicht.
Oder du verwendest eine schrittweise Methode, die automatisiert deine Variablen auswählt. Oder du nutzt eine Lasso- oder Ridge-Regression, um dem Overfitting entgegen zu wirken.
Du siehst, es gibt sehr viele Möglichkeiten und es hängt auch viel von der Größe deiner Stichprobe ab (wie komplex darf das Modell sein?), was deine Software kann (Lasso/Ridge?) und – falls zutreffend – was deine Betreuungsperson möchte.
LG Daniela
Hi Daniela,
ich rechne in meiner Masterarbeit ein GLMM. Es gibt eine Preanalysis, wo es 2 signifikante Kontrollprädiktoren gibt unter der Bedingung, dass p < 0.1. Diese nehme ich mit in meine Hauptanalyse und einer der Prädiktoren ist immer noch signifikant. Das Modell der Hauptanalyse hatte neben einer 3x fach Interaktion von Anfang an einen Kontrolprädiktor und dann eben die 2 Kontrollprädiktoren aus der Preanalysis. Die Haupt- und Additional Analysis unterscheiden sich eigentlich nur darin, dass in der Additional Analysis der eine initiale Kontrollprädiktor in die 3fach Interaktion kommt und der eine Prädiktor aus der Hauptanalyse der ehemaligen 3 fach Interaktion zum Kontrollprädiktor wird. Ich frage mich, was ich mit dem noch in der Hauptanalyse zusätzlichen signifikanten Kontrollprädiktor machen darf. Darf ich daraus schlussfolgern, dass Folgestudien den Einfluss dieses Kontrollprädiktors als ,,richtigen'' Prädiktor untersucht werden sollte? Ich verstehe nicht, wie ich einerseits sagen kann, durch die Aufnahme des Kontrollprädiktors kontrolliere ich seinen Einfluss, wenn er doch in der Hauptanalyse immernoch signifikant ist und damit ja meine Av erklärt. Ich hoffe, das war nicht zu verwirrend. Vielen Dank im Voraus!
Hallo Elma,
es macht für die statistische Analyse keinen Unterschied, ob eine unabhängige Variable ein „richtiger“ Prädiktor oder eine Kontrollvariable ist. Für die Statistik ist das genau das Gleiche. Nur die Interpretation ändert sind. Die Kontrollvariable willst du „nur“ kontrollieren, hier interessiert dich der Effekt an sich inhaltlich nicht.
Es kann aber ja gut sein, dass jemand anders in einer Folgestudie auch inhaltlich an diesem Prädiktor interessiert ist. Dann wird er ihn – genauso wie du jetzt – ins Modell mit aufnehmen, aber den Effekt dann eben auch inhaltlich interpretieren.
LG Daniela
Hallo,
Ich untersuche in meiner Masterarbeit die Wirkung zweier Werbestile (ironisch vs. sachlich) auf die Einstellung zur Marke in einem within-subjects-Design. Der Unterschied soll mit einem t-Test für abhängige Stichproben geprüft werden.
Nun möchte ich zusätzlich zwei Kontrollvariablen (z. B. Humorverständnis, Markenerfahrung) einbeziehen.
Frage:
Reicht dafür eine lineare Regression (Differenzwerte als AV), oder müsste ich auf eine ANCOVA umstellen – auch wenn es sich um ein Within-Design handelt?
LG
Aziz
Hallo Aziz,
es kommt auf die genaue Hypothese an. Wenn du eine Regression mit dem Differenzwert als AV rechnest, dann untersuchst du den Effekt der Kontrollvariablen auf die Veränderung der AV. Wenn du eine ANCOVA nimmst, wirst du ja die AVs der Einzelmessungen verwenden (also als Messwiederholung). Dann untersuchst du mit den Haupteffekten der Kovariaten den Effekt auf die AVs der Einzelmessungen. Den Effekt auf die Veränderung würdest du da nur über eine Interaktion abbilden, falls du das möchtest.
LG Daniela
Hallo Daniela,
ich führe im Rahmen meiner Masterarbeit eine moderierte Mediationsanalyse (Model 8) durch mit PROCESS und würde gerne auch auf Kontrollvariablen kontrollieren. Muss ich diese in der Analyse dann im Feld „Kovariaten“ zusätzlich ergänzen und der Rest des Models bleibt wie gehabt? Und sollte man alle Kontrollvariablen gleichzeitig einfügen oder getrennt nacheinander?
Lieben Dank vorab!
Hallo Mareen,
ja, genau. Die kommen ins Feld „Kovariaten“. Ob du ein Modell rechnest, in dem du gleich alle Kontrollvariablen einfügst, oder ob du mehrere Modelle rechnest (z.B. mit und ohne Kontrollvariablen, oder mit erst einer, dann zweien…), die du im Anschluss vergleichen willst, bleibt dir überlassen. Das kommt ganz darauf an, welche Story du damit erzählen willst, wieviel Platz du zum Berichten hast etc.
LG Daniela
Hey, ich hab eine Frage zum Bericht der Kontrollvariablen. Ich habe eine Mediationsanalyse gerechnet mit PROCESS von Hayes (single mediator model). Anschließend habe ich die Kontrollvariablen mit ins Modell aufgenommen. Es ergab sich kein großer Unterschied bei dem Einfluss der UV auf M und AV (blieben klein& nicht signifikant), jedoch hatte jede Kontrollvariable signifikant Einfluss auf die endogenen Variablen. Sollte ich gleich nur das Modell mit den KVs berichten oder erst das Modell ohne und dann das Modell mit? Und wie mache ich das mit der grafischen Darstellung? Ich wollte das mit Pfeilen und den Regressionskoeffizienten darstellen (aber nur für AV, UV, M), mache ich wenn ich beide Modelle berichte auf zwei grafische Darstellungen? Macht es zudem Sinn, sich die Kontrollvariablen dann näher anzuschauen beispielswiese mit stufenweise Regressionen? Vielen lieben Dank im Voraus.
Hallo Emily,
alles, was du genannt hast, kannst du machen, musst du aber nicht. Es kommt ganz darauf an, wieviel Platz du zum Berichten hast, wie wichtig diese Analyse innerhalb deiner Arbeit ist und welche Story du mit den Ergebnissen erzählen willst. Natürlich musst du aber immer drauf achten, dass du unverfälscht und transparent berichtest. So lange du das einhältst, hast du viele Möglichkeiten.
LG Daniela
Hallo Daniela,
ich stehe gerade irgendwie etwas auf dem Schlauch… Ist eine Variable automatisch eine Kontrollvariable, wenn ein signifikanter Zusammenhang mit der AV (oder auch der UV?) besteht? Eine Hypothese meiner BA ist, dass es einen negativen Zusammenhang zwischen Naturverbundenheit (NV) und Stresssymptomen gibt. Dass sich bei der Korrelationsanalyse gezeigt hat, dass es zwar einen signifikanten Zusammenhang gibt, der aber unerwarteter Weise genau andersrum ist, ist wahrscheinlich für meine Frage erstmal nicht relevant, aber ich erwähne es vorsichtshalber mal. Zusätzlich zeigten sich auch signifikante Korrelationen mit Geschlecht und Alter. Ich habe dann eine Partialkorrelation mit Geschlecht und Alter als KV gerechnet, was aber nicht großartig etwas an den vorherigen Ergebnissen geändert hat. Muss ich die beiden Variablen trotzdem als KV aufnehmen, weil ja ein Zusammenhang mit den relevanten Konstrukten besteht, oder brauche ich das nicht, wenn sich die Ergebnisse durch eine Partialkorrelation nicht groß verändern? Ich hoffe, meine Frage ist irgendwie verständlich…
Liebe Grüße,
Franziska
Hallo Franziska,
eine Kontrollvariable ist es dann, wenn du sie mit in dein Modell als UV aufnimmst, weil du dafür kontrollieren willst. Ob diese Kontrolle etwas am Ergebnis verändert oder nicht ist dafür erstmal egal.
„Kontrollvariable“ ist also nur ein Name, für eine Variable, die du – obwohl sie dich inhaltlich nicht interessiert – im Modell als UV hast.
Ob du eine Variable als Kontrollvariable einsetzen willst, kannst du unterschiedlich entscheiden. Beispielweise wie von dir beschrieben, weil sie eine signifikante Korrelation mit der AV hat. Aber du kannst sie auch aufnehmen, wenn es keine signifikant Korrelation besteht, einfach aus inhaltlichen Gründen (z.B. weil Vergleichsstudien sie auch kontrolliert haben).
In deinem Fall, wo du schon weißt, dass die Kontrolle der Variablen nichts am Ergebnis verändert, ist es egal, ob du das Ergebnis mit oder ohne Kontrollvariable berichtest. Und genau das solltest du aber auch so formulieren (dass du weißt, dass es keinen Unterschied macht).
LG Daniela