
Die Reliabilität einer Messung ist deren Verlässlichkeit. Sie gibt an, wie genau ein Merkmal gemessen wird und damit, ob die Daten reproduzierbar sind. Sie wird oft zur Qualitätskontrolle in psychologischen Tests, aber auch in medizinischen Untersuchungen eingesetzt.
Interessante Fragestellungen sind zum Beispiel:
- Werden Röntgenbilder von verschiedenen Ärzten verlässlich interpretiert?
- Werden die Persönlichkeitsmerkmale anhand einer bestimmten Skala von verschiedenen Psychologen verlässlich eingeschätzt?
- Werden Röntgenbilder vom gleichen Arzt verlässlich interpretiert?
- Schätzen Patienten ihre Persönlichkeitsmerkmale anhand einer bestimmten Skala verlässlich ein?
Frage 1 und 2 zielen dabei auf die Inter-Variabilität der Messung ab: Wie unterscheiden sich die Messungen zwischen den Beobachtern (Observer, Rater)?
→ Inter-Observer-Variability, Inter-Rater-Variability
Frage 3 und 4 fragen nach der Intra-Variabilität der Messung: Wie unterscheiden sich mehrere Messungen eines Beobachters?
→ Intra-Observer-Variability, Intra-Rater-Variability
Du willst mehr Durchblick im Statistik-Dschungel?
Zur Messung der Variabilität stehen verschiedene statistische Methoden zur Verfügung, die vom Skalenniveau der Daten abhängen und davon, ob es 2 oder mehr Observer/Messungen zu vergleichen gibt. Die folgende Tabelle gibt einen Überblick über eine Auswahl an statistischen Kennzahlen für die Reliabilität von Messungen.
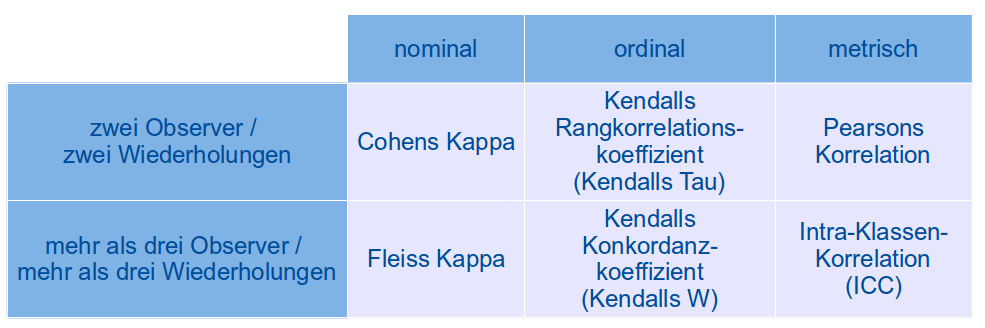
Außer dem Pearson-Koeffizient liegen alle Koeffizienten zwischen 0 und 1 und beschreiben nahe 1 einen starken Zusammenhang, das heißt eine gute Reliabilität. Nahe 0 bedeutet, dass die Messungen stark streuen und somit nicht verlässlich sind. Landis und Koch (1977) geben folgende Hilfestellung zur Interpretation der Koeffizienten als Grad der Übereinstimmung:
- 0 = poor
- 0 – 0.2 slight
- 0.2 – 0.4 fair
- 0.4 – 0.6 moderate
- 0.6 – 0.8 substantial
- 0.8 – 1 (almost) perfect
Der Pearson-Koeffizient liegt zwischen -1 und 1. Er beschreibt ebenfalls nahe 0 eine schwache Übereinstimmung und nahe 1 starke Übereinstimmung. Negative Werte sprechen für eine negative Korrelation, was zeigen würde, dass die Beurteilungen in gegengesetzte Richtungen korrelieren. Auch das gilt in diesem Kontext als schlechte Übereinstimmung.
Referenzen
- J. R. Landis, G. G. Koch: The measurement of observer agreement for categorical data. In: Biometrics. 33, 1977, 159-174.
- John Uebersax: Statistical Methods for Rater and Diagnostic Agreement. http://www.john-uebersax.com/stat/agree.htm

Ich bin Statistik-Expertin aus Leidenschaft und bringe Dir auf leicht verständliche Weise und anwendungsorientiert die statistische Datenanalyse bei. Mit meinen praxisrelevanten Inhalten und hilfreichen Tipps wirst Du statistisch kompetenter und bringst Dein Projekt einen großen Schritt voran.




P.S. Es scheint ja gängig zu sein, zumindest in der Sozialforschung, die Reliabilität von Likert Skalen mit cronbachs alpha zu berechnen – die ordinalen Daten werden als quasimetrisch angenommen, und von Normalverteilung ist häufig garnicht die Rede. Kann es sein, dass es in gewissen Zusammenhängen „ok“ ist, wenn auch statistisch nicht ganz korrekt?
Hallo Daniela
wie kann ich die Reliabilität einer Likertskala (4stufig) errechnen? Der cronbachs alpha ergibt Werte über .8, aber er gilt ja nicht bei ordinalskalierten Daten, oder? Es geht hier um die Güte des Messinstrumentes als solches.
Danke!
Hallo Anja,
Du darfst die Likert-Skala dafür verwenden. Das ist gängig so. Likert-Items werden wie metrische Messungen verwendet.
LG
Daniela
Hallo!
Ich habe da mal eine Frage.
Und zwar wüsste ich gerne, warum die Interrater-Reliabilität, die Spezifität sowie die Sensitivität wichtig für ein Messinstrument sind?
Insbesondere für eine Risikoskala.
Ich weiß schon, was sie bedeutend, wie man sie angibt etc. aber schlussendlich ist mir nicht richtig klar, was es in der Praxis bedeutet.
Sehr sehr gerne auch mit wissenschaftlichen Quellen 🙂
Hallo Vanessa,
eine Literaturstelle dazu habe ich nicht gefunden. Wenn du schon weißt, was sie bedeuten und wie sie berechnet werden, versuche ich es mal so:
Interrater-Reliabilität: Sie gibt an, wie zuverlässig die Beurteilung ist. Damit kann sicher gestellt werden, dass sie Beurteilung des Risikos mit dieser Skala nicht abhängig vom Beurteiler ist.
Sensitivität und Spezifität: Sie geben an, wie gut die Risikoskala tatsächlich Risikopatienten klassifiziert. Damit wird also beschrieben, wie gut der Test ist: Wie viele Fehler macht er? Wie oft ist er richtig? Bei Sensitivität bezogen auf die tatsächlichen Risikopatienten: Wie viele der tatsächlichen Risikopatienten werden auch als Risikopatient klassifziert? Bei der Spezifität bezogen auf die Nicht-Risiko-Patienten: Wie viele der tatsächlichen Nicht-Riskikopatienten werden als Nicht-Risikopatient klassifiziert?
Ich hoffe, das hilft weiter.
Gern kannst du auch unserer neu gegründeten Facebook-Gruppe Statistikfragen beitreten: https://www.facebook.com/groups/785900308158525/
Dort kannst du weitere Fragen stellen und mit mir und den anderen Teilnehmern darüber diskutieren.
Schöne Grüße
Daniela