
Sowohl bei Moderation als auch bei Mediation geht es um die Zusammenhänge zwischen drei Variablen X, Y und M. Untersucht wird der Effekt eines Prädiktors oder Faktors X (unabhängige Variable UV) auf ein Outcome Y (abhängige Variable AV). Das kann mit einem Regressionsmodell mit X als unabhängige und Y als abhängige Variable untersucht werden. Zusätzlich gibt es eine dritte Variable M. Sie ist entweder der Moderator oder der Mediator.
Je nach Art der abhängigen Variable wird die Analyse mittels linearer Regression (AV ist metrisch) oder logistischer Regression (AV ist dichotom) umgesetzt.
Moderation
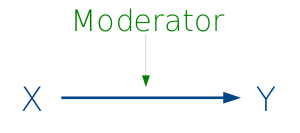
Bei der Moderation wirkt die dritte Variable M – der Moderator – auf die Beziehung zwischen X und Y. Der Einfluss von M ändert also den Effekt von X auf Y. Dies äußert sich so, dass die Beziehung zwischen X und Y je nach Ausprägung von M unterschiedlich ausfällt.
Statistisch gesprochen liegt eine Interaktion zwischen M und X vor. Und so wird die Moderation auch untersucht: Es wird ein Regressionsmodell mit den drei Faktoren gerechnet: X, M und die Interaktion zwischen X und M. Diese drei Faktoren wirken auf Y. Wird in diesem Modell die Interaktion signifikant, so liegt eine signifikante Moderation vor.
Du willst mehr Durchblick im Statistik-Dschungel?
Mediation
 Bei der Mediation steht der Mediator – die Variable M – in Beziehung sowohl zu X als auch zu Y. Der direkte Effekt zwischen X und Y wird durch den indirekten Effekt über M erklärt, also durch X -> M -> Y.
Bei der Mediation steht der Mediator – die Variable M – in Beziehung sowohl zu X als auch zu Y. Der direkte Effekt zwischen X und Y wird durch den indirekten Effekt über M erklärt, also durch X -> M -> Y.
Untersucht wird auf Mediation, indem mehrere Regressionsmodelle gerechnet werden. Wenn folgende Bedingungen erfüllt sind, liegt eine signifikante Mediation vor:
- im ersten Modell (X -> Y) ist der Regressionskoeffizient von X signifikant,
- im zweiten Modell (X -> M) ist der Regressionskoeffizient von X signifikant,
- im dritten Modell (X und M -> Y) ist der Regressionskoeffizient von M signifikant und
- im dritten Modell ist der Regressionskoeffizient von X kleiner als im ersten Modell.

Ich bin Statistik-Expertin aus Leidenschaft und bringe Dir auf leicht verständliche Weise und anwendungsorientiert die statistische Datenanalyse bei. Mit meinen praxisrelevanten Inhalten und hilfreichen Tipps wirst Du statistisch kompetenter und bringst Dein Projekt einen großen Schritt voran.




Liebe Frau Keller,
vielleicht können Sie auch mir bei meinem Problem weiterhelfen.
Im Rahmen meiner Masterarbeit würde ich gerne eine Mediation berechnen. Dafür muss natürlich zuerst bestätigt werden, dass die Pfade von UV –> AV, UV –> M und M –> AV signifikant miteinander zusammenhängen. Leider tun sie das nicht. Ich frage mich nun, wie ich rechtfertigen könnte dennoch mit den Rechnungen fortzufahren.
Über eine Antwort würde ich mich sehr freuen,
Liebe Grüße,
Carina
Hallo Carina,
eventuell deskriptiv? Sind die Regressionskoeffizienten vielleicht dennoch hoch, allerdings die Fallzahl nicht groß genug, um sie als signifikant nachzuweisen? Allerdings wird es dann trotzdem später nicht möglich sein, eine Mediation nachzuweisen.
Weitere Fragen könnt ihr gern in meiner Facebook-Gruppe Statistikfragen https://www.facebook.com/groups/785900308158525/ diskutieren.
Schöne Grüße
Daniela
Schöne Grüße
Daniela
Liebe Daniela,
darf ein Mediator auch dichotom sein (z.B. Geschlecht)?
Vielen lieben Dank im Voraus! 🙂
Ja.
Schöne Grüße
Daniela
Danke dir! 🙂
Liebe Daniela, schon einmal hast du mir weitergeholfen, jetzt wende ich mich noch einmal Hilfe suchend an dich. Ich untersuche, inwieweit Menschen ihre Leistung in einer Mathe-Aufgabe selbst vorhersagen können (über eine Persönlichkeitsfragebögen). Ich habe schon herausbekommen, dass es Geschlechtsunterschiede gibt: Bei Männern gibt es einen Zusammenhang, bei Frauen nicht – die Korrelationskoeffezenten unterscheiden sich zudem signifikant voneinander. Jetzt ist die Frage: Kann ich von einem Moderationseffekt des Geschlechts sprechen? Ich habe bereits für jedes Geschlecht getrennt Regressionen gerechnet, wie erwartet, war die bei Männern signifikant, bei Frauen aber nicht. Danke für deine Antwort und Grüße , Hans
Hallo Hans,
ja genau, das ist dann ein Moderationseffekt von Geschlecht. Du könntest das auch noch in einem gemeinsamen Modell untersuchen mit Faktor Geschlecht, Faktor Vorhersage und Interaktion Geschlecht*Vorhersage. Wenn signifikante Interaktion wäre dann der Moderationseffekt.
Schöne Grüße
Daniela
Vielen Dank, liebe Daniela! Das hat mir sehr geholfen.
Liebe Frau Keller,
vielen Dank auch von mir für den sehr verständlich geschriebenen Artikel.
Ich habe eine Frage bezüglich der Anforderungen an die Daten bei einer Moderationsanalyse mittel Process (Hayes). Müssen die Daten Normalverteilt sein? Ich finde dazu leider nichts in der Literatur.
Vielen Dank schon mal!
LG
Thomas
Hallo Thomas,
den Modellen liegen Regressionsmodelle zugrunde, die verschieden Voraussetzungen haben, unter anderem die Normalverteilung der Residuen (nicht direkt der Variablen).
Schöne Grüße
Daniela
Liebe Frau Keller,
Im Rahmen meiner Bachelorarbeit habe ich eine Untersuchung zum Rückschaufehler und den potenziellen Moderatir Empathie durchgeführt.
Grundlegend ist bei mir leider rein gar nichts signifikant geworden.
Nun habe ich eine wahrscheinlich sehr einfache Frage: Ist es überhaupt möglich eine Moderation festzustellen wenn überhaupt kein signifikanter Unterschied zwischen X und Y (ohne und mit Treatment) vorliegt?
Oder wäre ein signifikantes Ergebnis im erstes Schritt die notwendige Grundlage um überhaupt eine Moderation zu testen?
Liebe Grüße und vielen Dank im Voraus,
Marie
Hallo Marie,
ja, dann lässt sich hier wohl keine Moderation nachweisen. Vielleicht ist die Stichprobe dafür auch zu klein? Dann könntest Du mit den Ergebnissen zumindest deskriptiv arbeiten.
Weitere Fragen könnt Ihr gern in meiner Facebook-Gruppe Statistikfragen https://www.facebook.com/groups/785900308158525/ diskutieren.
Schöne Grüße
Daniela
Liebe Frau Keller,
vielen Dank auch von mir für den sehr verständlich geschriebenen Artikel.
Ich bereite mich gerade auf meine Masterarbeit in Psychologie vor.
Das Thema Yoga und Achtsames Essen sein.
Dafür führen wir eine online-Studie durch, die in einem Fragebogen Achtsames Essen erfasst.
Meine erste Hypothese ist, dass Yoga-Praktizierende höhere Werte bezüglich des achtsamen Essen zeigen, als nicht-Praktiziernde.
Eine weitere Hypothese wäre dann, dass der Zusammenhang von Yoga und Achtsamem Essen durch die Variable Körperbewusstsein mediiert wird.
Meine Frage ist, ob und wie sich das rechnen lässt.
Yoga wäre so ja eine kategoriale Variable im Sinne von Yoga-Praktizierender vs. nicht-Praktizierender. Kann ich damit eine Mediation rechnen?
Vielen Dank schon einmal!
Viele liebe Grüße
Laura
Hallo Laura,
wie sind denn die anderen Variablen erhoben? Welches Messniveau haben die?
Schöne Grüße
Daniela
Hallo Frau Keller,
wie ist das bei der Moderatoranalyse zu interpretieren, wenn ein Prädiktor und der Interaktionsterm signifikant werden, der andere Prädiktor aber nicht.
Inhaltlich möchte ich beide Prädiktoren als Moderator interpretieren.
Ich wäre sehr dankbar für eine Antwort.
Viele Grüße
Malena
Hallo Malena,
Interaktion signifikant bedeutet, es gibt eine signifikante Moderation. Beide Prädiktoren können dann als Moderator interpretiert werden, je nachdem, wie das inhaltlich passt.
Weitere Fragen gern in der Facebookgruppe Statistikfragen posten: https://www.facebook.com/groups/785900308158525/
Schöne Grüße
Daniela
Liebe Frau Keller,
ich konnte zumindest einen Teil der Frage lösen.
Auf einen Tipp hin, habe ich die Werte des Moderators getauscht (1=2 bzw. 2=1), so blieben alle Werte gleich, nur der Interaktionswert hatte nun ein positives Vorzeichen.
Vielleicht hilft das jemanden mit ähnlichem Problem weiter.
Hallo Frau Keller,
ich habe in meinem Modell folgende Ausgangssituation:
– eine Unabhängige Variable (Nominal, kodiert mit 0 und 1)
– eine abhängige Variable (metrisch)
– einen Moderator (Nominal, kodiert mit 0 und 1)
Leider finde ich nirgends Informationen, ob ich bei einer nominalen UV und einem nominalem Moderator eine lineare Regression durchführen darf oder nicht. Kann ich den Moderationseffekt auch mit dem Process Modell von Hayes untersuchen?
Vielen Dank für Ihre Antwort!
Hallo Christina,
ja, Process kann mit kategorialen unabhängigen Variablen und Moderatoren umgehen. Du könntest aber stattdessen auch eine mehrfaktorielle ANOVA rechnen, in der du für den Moderationseffekt den Interaktionsterm betrachtest.
Weitere Fragen können gern in meiner Facebookgruppe Statistikfragen diskutiert werden: https://www.facebook.com/groups/785900308158525/
Schöne Grüße
Daniela
Liebe Daniela,
ich beschäftige mich momentan mit der Mediation und der Konfundierung. Allerdings ist mir der Unterschied dieser beiden Modelle nicht ganz klar..
Bei der Konfundierung sage ich ja, dass eine Variable den Zusammenhang von UV und AV beeinflusst.
Bei der Mediation ist es aber ähnlich oder? Dort geht man doch davon aus, dass eine intervenierende Variable den Effekt der UV auf die AV vermittelt und somit auch den Zusammenhang beeinflusst.
Vielleicht könnten Sie mir bei dem konkreten Unterschied zwischen Konfundierung und Mediation weiterhelfen.
Herzlichen Dank und viele Liebe Grüße,
Eleo
Hallo Eleo,
ich weiß nicht genau, wie du Konfundierung definierst. Wenn es hier einfach um Störeffekte geht, dann würde ich sagen, dass sowohl Mediation als auch Moderation Spezialfälle von Störeffekten sind. Aus statistischer Sicht kann ich dazu noch sagen: für allgemeine Störvariablen muss nicht unbedingt die Richtung klar sein. Z.B. mit einer partiellen Korrelation können Störvariablen aus Zusammenhängen herausgerechnet werden, für die die Richtung nicht festgelegt wird. Bei Moderation und Mediation ist das anders. Hier ist ganz klar festgelegt, wie die Wirkungen verlaufen, siehe auch die Diagramme in diesem Blogbeitrag. Beantwortet das deine Frage?
Schöne Grüße
Daniela
Hallo Frau Keller,
danke für den informativen und gut geschriebenen Artikel – er hat mir sehr weitergeholfen. Könnten Sie mir bitte eine wichtige Frage beantworten, an der ich schon relativ lange verzweifle?
Sie beschreiben die Funktion eines Moderators…
Ist es möglich, eine Moderationsfunktion zu messen, wenn ich von einer umgedrehten U-förmigen Kurve ausgehe? D.h. ich gehe davon aus, dass X erst einen positiven Einfluss auf Y bis zu einem Optimum hat und dann einen negativen Einfluss. Nun möchte ich testen, wie M diese Beziehung moderiert.. ist das möglich?
Vielen lieben Dank schon einmal.
Viele Grüße,
Andrea
Hallo Andrea,
das ginge eventuell in einer nichtlinearen Regression.
Schöne Grüße
Daniela Keller
Hallo Frau Keller,
vielen Dank für Ihre tolle Seite erstmal. Die hat mir schon viel weitergeholfen.
Ich rechne derzeit für meine Masterarbeit eine Moderatorenanalyse mit einer intervallskalierten Variable als Outcome (Beziehungszufriedenheit nach 10 Jahren), einer intervallskalierten Variable als Prädiktor (Beziehungszufriedenheit bei Baseline Assessment) und mehreren möglichen intervallskalierten Moderatoren (protektive Faktoren gegen Depression in disharmonischen Beziehungen).
Ich habe das Ganze mit dem PROCESS Makro gemacht, also Schritt für Schritt mögliche signifikante Interaktionen getestet.
Ergebnis: Interaktionen werden nicht signifikant, nur die protektiven Faktoren als Haupteffekte selbst.
Da bin ich mir etwas unsicher, was genau das bedeutet und wie ich das interpretieren soll- moderieren diese Variablen den Effekt von Prädiktor auf Outcome Variable oder heißt das, es besteht keine Moderation und die protektiven Faktoren wirken sich unabhängig von der Prädiktorvariable (Beziehungszufriedenheit Baseline) auf die Outcome Variable aus?
Ich hoffe Sie können mir helfen. Vielen Dank für Ihre Hilfe schon mal!
Eva B.
Edit: Depression nach 10 Jahren ist Outcome Variable
Hallo Eva,
wenn die Interaktion nicht signifikant ist, liegt keine Moderation vor. Für weitere spezielle Fragen kannst du meine Facebookgruppe Statistikfragen nutzen: https://www.facebook.com/groups/785900308158525/
Schöne Grüße
Daniela
Hallo Frau Keller,
erst einmal vielen Dank für die verständliche Erklärung, es ist toll, dass Sie komplexe Themen verständlich aufbereiten.
Ich beschäftige mich derzeit mit einer Mediation und bin bei der inhaltlichen Interpretation der Ergebnisse etwas unsicher.
1) (X -> Y):Regressionskoeffizient von X ist signifikant
2) (X -> M): Regressionskoeffizient von X ist signifikant
3) (X und M -> Y): Regressionskoeffizient von M ist signifikant und
der Regressionskoeffizient von X kleiner als im ersten Modell und NICHT signifikant.
aus 3) lässt sich meiner Kenntnis nach schließen, dass eine vollständige Mediation vorliegt. Mein Problem ist nun was das inhaltlich heißt: Bedeutet das, dass X eigentlich gar nicht auf Y wirkt, sondern eben nur indirekt, indem X auf M wirkt und M wiederum auf Y? Drückt sich daher z.B. eine Steigerung in X nur durch die Erhöhung von M aus (wenn man annimmt das der Regressionskoeffizient hier positiv ist)?
Wie ließe sich das im Fall einer partiellen Mediation interpretieren?
Ich wäre sehr dankbar für eine Antwort !
Liebe Grüße,
Annika Bräunle
Hallo Annika,
für spezielle Fragen kannst du meine Facebookgruppe Statistikfragen nutzen: https://www.facebook.com/groups/785900308158525/
Dort tummeln sich viele mit ähnlichen Problemen und auch Antworten dazu und ich schaue auch regelmäßig vorbei.
Schöne Grüße
Daniela
Hallo Daniela,
ich habe für meine Masterarbeit eine serielle Mediatoranalyse mit insgesamt zwei Mediatoren druchgeführt (X-M1-M2-Y) und bin mir im Moment unsicher bei der Interpretation der Ergebnisse.
Die Pfadanalyse ergab, dass der indirekte Effekt, der über beide Mediatoren führt, signifikant wird. Der direkte Effekt hingegen nicht. Es ist hierbei so, dass die unabhängige Variable X positiv mit dem ersten Mediator zusammenhängt, dieser jedoch negativ mit dem zweiten und der zweite Mediator wiederum negativ mit der abhängigen Variable. Demnach würde ja ein Anstieg in X einen Anstieg in M1 ergeben, dieser würde jedoch zu einer Reduktion von M2 führen, was wiederum in einem verminderndem Effekt in Y resultieren würde? Wäre diese Interpretation so richtig?
Außerdem ist mir nicht ganz klar, wie ich die einzelnen Pfade interpretiere, die in dem Modell nicht signifikant geworden sind?
Ich hoffe, du kannst mir weiterhelfen.
Vielen Dank und schöne Grüße,
Katharina
Liebe Katharina,
für spezielle Fragen, nicht direkt zum Blogbeitrag hier, kannst du meine Facebookgruppe Statistikfragen nutzen: https://www.facebook.com/groups/785900308158525/
Schöne Grüße
Daniela
Liebe Daniela,
Ich hänge grade etwas bei der Interpretation meiner Ergebnisse, vielleicht kannst du mir helfen.
ich rechne grade im Rahmen meiner Masterarbeit eine binäre logistische regression. Meine AV ist rückfällig ja/nein
Meine Uvs sind soziale Unterstützung, Selbstwirksamkeit, Abhängigkeit, Geschlecht, Alter und soziale Unterstützung *Selbstwirksamkeit (also Interaktionsvariable) und soziale Unterstützung * abhängige im Freundeskreis (ebenfalls Interaktionsvariable).
Wie interpretiere ich jetzt die Odds, B (z.B. ,117) bzw. den Odds ratio Exp(B) (z.B 1,129) für bspw. die Interaktionsvariable soziale Unterstützung* Selbstwirksamkeitserwartung? Bei den „einfachen“ Variablen ist mir das klar, nur bei den Interaktionseffekten hänge ich irgendwie.
Viele liebe Grüße
Lou
Liebe Lucia,
für spezielle Fragen, nicht direkt zum Blogbeitrag hier, kannst du meine Facebookgruppe Statistikfragen nutzen: https://www.facebook.com/groups/785900308158525/
Schöne Grüße
Daniela
Liebe Frau Keller,
auch ich schließe mich an, Ihre Seite ist sehr hilfreich!
Im Rahmen meiner MA führe ich Mediator- und Moderatoranalysen durch. Dazu habe ich zwei Fragen.
1. Zur Mediatoranalyse: Wenn der Mediator (metrische Variable) in der multiplen Regressionsanalyse signifikant (p= .001) und die unabhängige Variable (dichotome Variable) tendenziell signifikant (p= .053) wird: Handelt es sich hier dann trotzdem um eine vollständige Mediation?
2. Zur Moderatoranalyse: Wenn meine UV und mein potenzieller Moderator jeweils dichotom sind, ist es sinnvoll die Moderatoranalyse per Regression durchzuführen? Ich habe gelesen, dass der Moderatoreffekt bei dichotomen Moderatoren auch geprüft werden kann, indem der Datensatz auf der Basis des Moderators geteilt wird und dann Korrelationen durchgeführt werden. Anschließend wird geprüft, ob sich die beiden Korrelationskoeffizienten signifikant voneinander unterscheiden. Ist dieses Vorgehen so richtig? Ich bin mir sehr unsicher, da ich zur Moderatoranalyse bei dichotomen Variablen bisher nichts in der Fachliteratur gefunden habe. Über einen Tipp wäre ich sehr dankbar!
Liebe Grüße
Janine
Hallo Janine,
zu 1) solche Grenzfälle kannst du diskutieren und darauf hinweisen, dass der p-Wert knapp ist. Eindeutig ist dieses Ergebnis dann nicht.
zu 2) Gibt es hier nur diesen dichotomen Faktor und den dichotomen Moderator und sonst keine UV? Dann könntest du auch eine ANOVA mit Interaktion rechnen. Der signifikante Interaktionseffekt wäre dann die Moderation.
Schöne Grüße
Daniela
Liebe Daniela,
ich finde deine Seite ganz großartig und hab schon viele hilfreiche Kommentare für meine MA gefunden! Vielen Dank dafür!
Meine Frage bezieht sich auf die Interaktion zweier dichotomer Variablen (jeweils 0-1 kodiert) und ob die Multiplikation Var1*Var2 über Werte berechnen tatsächlich das bewirkt, was ich für die multiple Regression möchte: nämlich die Interaktion, wenn beide Var 1 sind.
Hab schon vorab vielen Dank für eine baldige Antwort!
Liebe Grüße,
Elke
Hallo Elke,
wie sieht der Rest deiner Regression aus? Welche Arten an Parametern hast du hier? Wie sind Var1 und Var2 kodiert?
Schöne Grüße
Daniela
Hallo Frau Keller,
ich habe eine Frage zur Moderation.
Und zwar habe ich eine nominale UV1 und eine metrische AV. Die Varianzanalyse ergab leider keinen signifikanten Effekt (p>.05).
Nun habe ich eine weitere ordinale UV2 als zusätzlichen Faktor mit in das Modell gebracht.
Dabei erhielt ich einen signifikanten effekt der UV2 und ebenfalls einen signifikanten effekt zwischen UV1*UV2. Der Effekt von UV1 ist allerdings weiterhin nicht signifikant und nur noch größer geworden.
Da ich gelesen habe, dass ein Moderationseffekt vorliegt, wenn die Interaktion signifikant ist wollte ich fragen, ob dies in meinem Fall auch der Fall ist? und wie ich das interpretieren kann, da ich ja eig. gar keinen Effekt von UV1 auf die AV habe. Somit kann die UV2 doch eigentlich gar nicht moderieren?
lassen sich in meinem Fall dann Interaktionen gar nicht interpretieren?
Mit freundlichen Grüßen
Marlene
Hallo Marlene,
ich denke die Interaktion kannst du trotzdem als Moderationseffekt interpretieren. Eventuell sind die p-Werte auch knapp bzw. die Stichprobe klein? Das könnte auch der Grund für widersprüchliche Ergebnisse sein.
Schöne Grüße
Daniela
Liebe Frau Keller,
wenn ich einen Moderationseffekt des Interaktionsterms finde, wie wird dieser üblicherweise dargestellt?
Eignet sich ein Diagramm bzw. wie würde dieses aussehen?
Vielen Dank und beste Grüße
Lisa
Hallo Lisa,
das kommt auf den Variablentyp an. Bei kategorialen Variablen sind teilweise Diagramme möglich. Wenn es sich nur um metrische Variablen handelt, wird das schwieriger. Dann kann man eine Variable (Moderator) eventuell dichotomisieren und dann ein zweifarbiges Streudiagramm erstellen.
Schöne Grüße
Daniela
Hallo Frau Keller,
ich muss mich den Loben der anderen anschließen!
Nun habe ich auch eine Frage zur Mediatoranalyse mit einer univariaten Varianzanalyse.
Ich habe in meinem Experiment eine UV (X) und eine AV (Y). Des Weiteren habe ich zwei Mediatorvariablen Texterleben (M1) und strukturelle Verständlichkeit (M2).
Nun habe ich für jede Mediatorvariable einzeln diese vier Modelle gerechnet. Dabei kam raus:
1. Modell (X -> Y) X nicht signifikant,
2. Modell (X -> M1) X nicht signifikant,
3. Modell (X und M1 -> Y) M nicht signifikant (.079) und X größer als im ersten Modell.
2. Modell (X -> M2) X signifikant,
3. Modell (X und M2 -> Y) M nicht signifikant und
X kleiner als im ersten Modell.
heißt dass nun, dass ich definitiv keinen Effekt von der UV auf die AV habe und auch keinen Effekt beider Mediatorvariablen?
und wenn ich noch metrische moderatorvariablen habe muss ich diese dann bei Kovariate oder bei faktoren eintragen? und immer jeweils einzeln dann?
Liebe Grüße
Marlene
Hallo Marlene,
ja, hier sieht es so aus als könntest du keine signifikanten Effekte nachweisen. Metrische Faktoren werden in der ANOVA bei „Kovariate“ eingetragen.
Schöne Grüße
Daniela
Liebe Daniela,
auch ich habe gerade ein paar Schwierigkeiten mit der Bildung von Interaktionstermen.
Also ich habe eine metrische AV, eine dichotome UV1 (krank: ja / krank: nein) und eine weitere metrische UV2 (Alter). Ich benötige nun einen Interaktionsterm aus UV1 und UV2. Allerdings möchte ich für die zwei Gruppen krank: ja und krank: nein eine getrennte Interaktionsvariable. Sprich: eine Interaktionsvariable für Personen, die krank sind und eine weitere Interaktionsvariable für die Personen, die nicht krank sind.
Ich kenne leider nur den normalen Befehl für einen Interaktionsterm ohne Gruppentrennung (in meinem Beispiel: Krankheit * Alter).
Ich hoffe Du kannst mir helfen.
Herzlichen Dank und schöne Grüße,
Eleo
Hallo Eleo,
das verstehe ich nicht. Was willst du mit dieser getrennten Interaktionsvariablen??
Schöne Grüße
Daniela
Das hat sich schon erledigt. Ich stand an dem Tag auf dem Schlauch 🙂
Vielen Dank trotzdem!
Liebe Daniela,
ich hätte nun leider doch noch eine Frage zur Interpretation von Interaktionseffekten.
Dummy*Kategoriale Variable
Dummy: 0= krank; 1=gesund
Kategoriale Variable: Bildung (Referenz: niedrige Bildung)
Interpretiere ich die Interaktion aus gesund*hoheBildung richtig?
–> GesundePersonen mit hoher Bildung sind glücklicher als kranke Personen mit hoher Bildung.
Oder muss ich mich hier auf die Referenzkategorie beziehen und folgendes sagen:
–> Gesunde Personen mit hoher Bildung sind glücklicher als kranke Personen mit niedriger Bildung?
Zudem habe ich in einigen Studien feststellen können, dass der Koeffizient des konditionalen Effektes und der Koeffizient des Interaktionseffekts addiert werden. Anschließend wird dieser Wert für die Analysen verwendet.
Hier: Koeffizient hohe Bildung + Koeffizient gesund*hoheBildung
Aber wie sieht die Interpretation an dieser Stelle aus?
–> Gesunde Personen mit hoher Bildung sind glücklicher als gesunde Personen mit niedriger Bildung?
Ich bedanke mich vorab schon ganz herzlich!
Beste Grüße
Eleo
Hallo Eleo,
die signifikante Interaktion bedeutet, dass der Effekt der einen Variablen von der anderen Variablen beeinflusst wird. Was genau das in deinem Fall bedeutet siehst du dir am besten deskriptiv an, indem du dir die Mittelwerte der abhängigen Variablen für die Kombinationen der beiden Faktoren ansiehst. Damit kannst du den Interaktionseffekt dann interpretieren.
Die Addition der Koeffizienten kenne ich nicht. Wenn du hier ein Beispiel hast, kannst du mir das gern mal schicken.
Schöne Grüße
Daniela
Also mir leuchtet die Bedeutung des signifikanten Interaktionseffektes zwar ein, allerdings weiß ich nicht, wie ich mit der Interpretation umgehe, wenn an der Interaktion eine kategoriale Variable beteiligt ist.
Wie oben bereits beschrieben schwanke ich zwischen folgenden zwei Interpretationsmöglichkeiten:
Dummy: 0= krank; 1=gesund
Kategoriale Variable: Bildung (niedrig, mittel, hoch) (Referenz: niedrige Bildung)
Interpretiere ich die Interaktion aus gesund*hoheBildung richtig?
–> GesundePersonen mit hoher Bildung sind glücklicher als kranke Personen mit hoher Bildung.
Oder muss ich mich hier auf die Referenzkategorie beziehen und folgendes sagen:
–> Gesunde Personen mit hoher Bildung sind glücklicher als kranke Personen mit niedriger Bildung?
Für die Addition der Koeffizienten:
http://www.ls4.soziologie.uni-muenchen.de/studium_lehre/lehrveranst/quanti_2/m2_vorlesung_09.pdf
–> z.B. Folie 41
Hallo,
in welche Richtung der Effekt geht, kann man allein aus der Signifikanz nicht herauslesen. Dazu musst du dir die deskriptiven Werte gruppiert ansehen.
Aber ja: es muss immer zur Referenzkategorie verglichen werden.
Schöne Grüße
Daniela
Sehr geehrte Frau Keller,
vielen Dank für Ihren tollen Beitrag! Kann es bei der Moderatoranalyse Probleme geben, wenn ich bei einem dichotomen Moderator (0 vs. 1) verschiedene Stichprobengrößen habe? Also z.B. für die Ausprägung 0, N = 2000, und für die Ausprägung 1, N = 600 ? Oder wird das durch eine Gewichtung und durch die Z-Standardisierung ausgeglichen?
Lieben Gruß
Joleena
Hallo Joleena,
bei diesen Größen gibt es keine Probleme, da auch in der „kleinen“ Gruppe noch sehr viele Daten vorhanden sind.
Schöne Grüße
Daniela
Hallo Daniela,
Vielen Dank!!! 🙂
Viele Grüße
Joleena
Liebe Daniela,
kennst du dich mit dem SPSS Macro Process auch aus?
Ich habe ein komplexes Modell, bei dem ich insgesamt vier Mediatoren und drei Moderatoren habe, wobei die drei Moderatoren die Mediatoren beeinflussen, also eine moderierende Mediation.
In Process gibt es insgesamt an die 72 Modelle, vlt kannst du mir sagen, welches Modell ich verwenden muss?
Lieben Dank im Voraus und schöne Grüße
Maria
Hallo Maria,
dazu kann ich spontan keine Antwort geben. Versuche es doch mal in der Facebook-Gruppe Statistikfragen https://www.facebook.com/groups/785900308158525/ Da tummeln sich einige, die schon viel mit Process gearbeitet haben. Vielleicht weiß da jemand direkt Rat.
Schöne Grüße
Daniela
Lieben Dank, Daniela! 🙂
Guten Abend Frau Keller,
ich habe zwei Frage zur die Moderator-Analyse via Linearer Regression.
Ich habe zwei Gruppen X und Y und untersuche wie sich diese beiden Gruppen in einer Outcome Variable unterscheiden. Das es einen signifikanten Unterschied gibt habe ich per T-test bereits herausgefunden. Jetzt will ich eine mögliche Moderation auf die Differenz der beiden Mittelwerte prüfen. Geht das überhaupt? Ich habe keinerlei Beispiel finden können, weder im Internet noch in Lehrbüchern. Oder muss ich Moderationen einzeln prüfen, also einmal auf den Zusammenhang „Mitgliedschaft in Gruppe X –> Outcome-Variable“ und einmal das Ganze noch für Gruppe Y
Vielen Dank schonmal im Voraus
Viele Grüße
Thomas
Hallo Thomas,
was soll die Moderator-Variable sein? Welches Messniveau hat die?
Schöne Grüße
Daniela
Hallo Frau Keller,
ich laufe derzeit bei meiner Diskussion fest, vl. können Sie mir da weiterhelfen. Und zwar habe ich untersucht, ob das Altersbild soziale Verluste oder das Altersbild körperliche Verluste moderierend auf den Zusammenhang zwischen sozialer Isolation und Einsamkeit wirkt. Heraus kam, dass das Altersbild körperliche Verluste moderierend wirkt, während das Altersbild soziale Verluste nicht moderierend wirkt. Da das Altersbild soziale Verluste sowohl mit sozialer Isolation als auch mit Einsamkeit einzeln korreliert, das Altersbild körperliche Verluste hingegen nur mit Einsamkeit, hingegen nicht mit sozialer Isolation, hätte ich eher erwartet, dass das Altersbild soziale Verlust als Moderator fungiert. Ist Verwunderung über das Ergebnis unbegründet? Oder finden Sie das Ergebnis ebenfalls unerwartet?
Würde mich über eine Antwort freuen,
herzliche Grüße
Christiane
Hallo Christiane,
das kann durchaus vorkommen. Bei der Moderation geht es ja nicht um die direkten Zusammenhänge sondern um einen Effekt AUF einen Zusammenhang. Insofern passt das schon. Außerdem kann es natürlich sein, dass die Effekte knapp signifikant/nicht signifikant sind, was man auch diskutieren könnte. Aber so weit kenne ich die Daten ja nun nicht…
Schöne Grüße
Daniela
Weiterführende Fragen könnt ihr gern mit mir und den anderen Teilnehmern in der Facebook-Gruppe Statistikfragen diskutieren. Hier der Link: https://www.facebook.com/groups/785900308158525/
Ich möchte meine Frage von vorhin erweitern:
Wenn das Treatment X ein Interaktionsterm ist (Veränderung von Zeitpunkt 1 zu 2 x Gruppenzugehörigkeit Treatment oder nicht), d.h. ich möchte wissen, ob das Treatment die Variable Y (Motivation) verändert, muss ich dann auch im zweiten und dritten Schritt die Interaktion zwischen Unterricht und Zeit, d.h. die Veränderung des Unterrichts als Mediatorvariable nehmen, wenn ich wissen will, ob die Veränderung aufgrund des Treatments über den Unterricht mediiert wird? Oder kann ich auch den Unterricht über beide Zeitpunkte (d.h. keinen Interaktionsterm) im 3. Modell verwenden?
Vielen Dank.
Britta
Vielen Dank
Vielen Dank
Spontan würde ich sagen: Unterricht alleine als Mediatorvariable verwenden. Ganz klar ist mir die Forschungsfrage und die Daten aber im Moment nicht und dann lässt sich das nur schwer beantworten..
Ich habe auch eine Frage zu einem Mediatormodell.
Wie ist es zu interpretieren, wenn im Modell
1. X (Treatment) –> Y (Motivation) X nicht signifikant ist.
2. X (Treatment) –> M (Unterricht) X signifikant ist.
3. X (Treatment) und M (Unterricht) –> Y nun X signfikant ist.
Kann man dann sagen, dass M (Unterricht) einen möglicherweise negativen Effekt von X (Treatment) kompensiert? Ist das noch ein Mediatoreffekt?
Vielen Dank für die Interpretation.
HG Britta
Das würde ich nicht als Mediatoreffekt interpretieren. M ist in dem Fall ja kein Vermittler des Effekts.
Liebe Daniela,
danke für die verständliche Aufbereitung des Themas.
Ich habe jetzt mehrere Regressionsmodelle durchgerechnet und habe im Schritt 4 einen kleinere Regressionskoeffizienten für X erhalten. Allerdings ist der Unterscheid sehr klein (1,47 im Modell 3 vs. 1,38 im Modell 1). Ist es relevant, dass die Unterschiede so gering ausfallen?
Viele Grüße,
Sebastian
Der Unterschied ist wirklich sehr gering. Wenn du die Konfidenzintervalle dazu betrachtest, siehst du, ob er signifikant ist (wenn sie sich nicht überschneiden).
danke für die schnelle Antwort.
Mit dem Vergleich der Konfidenzintervalle sind die Konfidenzintervalle von X zwischen Modell 1 und 3 gemeint?
Die Konfidenzintervalle des Regressionskoeffizienten von X, einmal im Modell 1 und einmal im Modell 3.
nochmal vielen Dank
Liebe Daniela,
ich habe eine Moderatoranalyse mit PROCESS von Hayes (2013) gerechnet. Das Gesamtmodell dieser Moderatoranalyse ist signifikant, aber die Interaktion nicht, es liegt also kein Moderator vor. Aber wie interpretiere ich dann, dass das Gesamtmodell signifikant war?
Für eine Antwort bin ich extremst dankbar!
Hallo Julia,
das bedeutet, dass das Modell gut auf deine Daten passt, also eine bessere Güte als ein komplettes Zufallsmodell hat.
Schöne Grüße
Daniela
Hallo Daniela,
ich habe ebenfalls eine Moderatoranalyse mit Process berechnet, wobei das Gesamtmodell signifikant ist und der Interaktionsterm jedoch mit p=.074 nicht signifikant ist. Im Feld „Conditional effect of X on Y at values of the moderator(s)“ wiederum sind alle Effekte höchst signifikant. Wie kann ich das interpretieren?
Ich freue mich über Hilfe 🙂
Hallo Sina, meinst du die Interpretation des Interaktionsterms? Der ist eben nicht signifikant, allerdings knapp. Bei größerer Stichprobe hättest du wohl einen signifikanten Interaktionseffekt gesehen.
Schöne Grüße
Daniela
Sehr geehrte Frau Keller,
ist zwar überhaupt nicht zum Thema, ich habe aber eine Frage die mich bereits den ganzen Tag quält und ich finde keine Antwort darauf. Darum probiere ich es hier.
Ich würde mittels SPSS gerne mehrere dichotome Variablen mittels gestapeltem Balkendiagramm darstellen. Sodass ich in einem Balken zutreffende Fälle in %, nicht zutreffende Fälle in % und fehlende Werte in % erhalte.
Wäre froh wenn sie mir weiterhelfen könnten.
Vielen Dank im Voraus
Hallo Christian,
sollen die mehreren dichotomen Variablen in ein gemeinsames Diagramm oder für jede Variable ein eigenes?
Schöne Grüße
Daniela
Hallo Daniela,
wau das ging ja schnell…alle drei dichotomen Variablen sollten ins selbe Diagramm, jedoch sollte jede Variable durch einen eigenen Balken repräsentiert werden. Die Einzelvariante wäre aber auch interessant.
Vielen lieben Dank
lg Christian
Hallo Christian,
über Grafik -> Alte Dialogfelder -> Balken kann man eingeben, dass man „Auswerten über verschiedene Variablen“ möchte. Damit bekommst du mehrere Variablen in ein Diagramm. In das Feld „Bedeutung der Balken“ nimmst du dann alle Variablen auf. Dort kannst du dann die „Statistik ändern“, je nachdem, was du möchtest: Mittelwert ergibt den Prozentsatz der 1er, wenn du 0/1 kodiert hast, oder du definierst dir selbst Prozentsätze, die du sehen willst. Allerdings weiß ich nicht, ob man sich als gestapeltes Diagramm die 0er und 1er angeben lassen kann. Gestapelte sind eigentlich nur für weitere Gruppierungen mit einer weiteren Variabel (z.B. Geschlecht) gedacht.
Für weitere Fragen kannst du dich gern in meiner Facebook Gruppe Statistikfragen melden, oder du mailst mir für eine Beratung.
Schöne Grüße
Daniela
Hallo Frau Keller,
ich habe eine eher allgemeine Frage. Mir ist der Unterschied zwischen beiden immer noch nicht ganz klar.
Folgendes Forschungsszenario:
X: Sozioökonomische Faktoren (z.B. Geschlecht)
Y: Teilnahme an Weiterbildung
M: Wirtschaftssektoren in Deutschland
Handelt es sich dann bei M um einen Mediator- oder Moderatorvariable?
Einige sozioökonomische Faktoren treten dabei nur in einem einzigen Sektor auf, andere variieren zwischen diesen.
Vielen Dank schon im Voraus.
Hallo Sebastian,
ich vermute, es ist eine Moderation: Der Wirtschaftssektor beeinflusst die Beziehung zwischen Sozioökonomischen Faktoren und Weiterbildung. Für eine Mediation müssten die Sozioökonomischen Faktoren auf den Wirtschaftssektor und dieser dann auf die Weiterbildung wirken. Das passt nicht, oder?
Schöne Grüße
Daniela Keller
Hallo!
Zum Thema Moderation hätte ich auch noch eine Frage:
Wenn ich zwei Prädiktorvariablen für eine Kriteriumsvariable habe und u. a. auch testen möchte, ob die beiden Prädiktoren bei der Vorhersage interagieren, dann teste ich ja den Interaktionsterm auf Signifikanz. Wenn aber nun beide Prädiktoren theoretisch jeweils als Moderatorvariable in Bezug auf die Beziehung des anderen Prädiktors zur abhängigen Variable in Frage kommen, wie kann man das auseinanderhalten? Statistisch ist die Interaktion ja ein Produktterm, das heisst doch dass man bei einer signifikanten Interaktion gar nicht sagen kann, wer Moderator und wer Prädiktor ist, oder? So wie 3×5 dasgleiche ist wie 5×3. Und das wiederum hiesse, dass Hypothesen wie
H1 a) Y moderiert den Zusammenhang zwischen X und Z
H1 b) X moderiert den Zusammenhang zwischen Y und Z
nicht so viel Sinn haben, wenn rein statistisch in beiden Hypothesen dasgleiche drin steckt.
Ja, H1a und H1b werden aus statistischer Sicht mit genau der gleichen Analyse untersucht. Die Frage, wer Moderator und wer Prädiktor ist, ist rein inhaltlich.
Gute Tag Frau Keller,
ich habe einige Fragen die mir schlaflose Nächte bereiten. Leider konnte ich bisher in der Literatur keine Antwort finden und hoffe nun, dass Sie mir helfen können.
Ich möchte eine Mediatoranalyse durchführen bei der X eine Interaktionsvariable (Moderator) ist. Gelten die von Ihnen oben aufgeführten Bedingungen zur Mediation
“ – im ersten Modell (X -> Y) ist der Regressionskoeffizient von X signifikant,
– im zweiten Modell (X -> M) ist der Regressionskoeffizient von X signifikant,
– im dritten Modell (X und M -> Y) ist der Regressionskoeffizient von M
signifikant und
– im dritten Modell ist der Regressionskoeffizient von X kleiner als im ersten
Modell “
auch in diesem Fall uneingeschränkt? Oder muss bei der Interprätation der Regressionskoeffizienten etwas anderes beachtet werden? Sind dabei eventuell die Werte der Variablen aus denen die Moderatorvariable gebildet wurde zu beachten?
Vielen, vielen Dank im Voraus!
Hallo Katja,
grundsätzlich ja: die Bedingungen gelten genauso. Allerdings klingt Ihre Frage so, also wäre das Modell insgesamt noch komplexer, deshalb habe ich noch ein paar Nachfragen: Die bei mir X genannte Variable ist bei Ihnen demnach eine Interaktionsvariable. Haben Sie die demnach als Produkt im Modell eingebaut? Haben Sie dann die beiden ursprünglichen Variablen auch als Faktoren im Modell?
Schöne Grüße
Daniela Keller
Hallo Frau Keller,
erst Mal. Danke für Ihre Antwort!
Ja, Sie verstehen das völlig richtig. Sowohl die Interaktionsvariable (Produkt) als auch die ursprünglichen Variablen sind im Modell (diese müssen ja soweit ich weiß kontrolliert werden, damit der Interaktionseffekt überhaut interpretierbar wird).
Um das Ganze zu veranschaulichen ein einfaches Bsp: Mit steigenden „Alter“ steigt das „Einkommen“ (Y). Dies gilt besonders,wenn man „männlich“ ist (age * sex = X) Diese Beziehung wird durch „Arbeitserfahrung“ (M1) und „Elternzeit“ (M2) mediiert.
Mich würde dabei folgendes interessieren:
Zur Bedingung bzw. Modell 1: Mich interessiert vor allem der Interaktionseffekt. Daher würde ich hier die Effekte der Ursprungsvariablen nicht interpretieren. Die Bedingung muss nur in Bezug auf die Interaktionsvariable erfüllt sein. Ist das korrekt?
!!! Zu 2 !!!!: Ich gehe davon aus, dass hier nicht unbedingt die Interaktionsvariable (age* sex) als X berechnet werden muss. Je nachdem was theoretisch plausibel ist, kann auch eine der Ursprungsvariablen X sein.
Z.B: „age“ (x1)–> „Arbeitserfahrung“ (M1)
oder „sex “ (x2) –> „Elternzeit“.Ist das richtig?
Zu 3: Hier würde ich die Werte der Urprungsvariablen auch nicht interpretieren. Die Bedingung muss nur in Bezug auf die interaktionsvariable erfüllt sein oder?
viele Grüße, Katja
Hallo Katja,
zu 2: es müssen alle Bedinungen für die Interaktionsvariable gelten. Also auch im Modell 2 wirkt „age*sex“ auf M.
zu 1 und 3: Ja, die Bedingungen müssen nur für die Interaktionsvariable erfüllt sein.
Schöne Grüße
Daniela
VIELEN DANK!!! Sie haben mir damit sehr geholfen!
Liebe Frau Keller,
Danke erstmal, dass sie sich bemühen statistische Zusammenhänge verständlich zu erklären.
Trotzdem habe ich eine Frage.
Wo ist der Unterschied ob ich eine eine Regressionsanalyse rechne, um den Einfluss der Moderatorvariablen zu errechnen oder ob ich diese bei einer MANOVA die ich eh machen muss als Kovariate einsetze?
Viele Grüße Anna
Hallo Anna,
die Regressionsanalyse und die MANOVA unterscheiden sich vor allem dadurch, dass es bei erster eine abhängige Variable gibt. Die MANOVA untersucht gleichzeitig mehrere abhängige Variablen. Die Kovariate oder Moderatorvariable ist jeweils ein Faktor dieser beiden Modelle. Die Idee, die hinter diesem Faktor steht, ist die gleiche.
Schöne Grüße
Daniela Keller
Liebe Frau Keller,
ich rechne eine 2 faktorielle ANOVA mit Bootstrapping. Nun habe ich aber Probleme den SPSS Output zu interpretieren. Bezüglich den beiden Haupteffekte finde ich keine F-Werte sowie keine Effektstärken. Bezüglich der Wechselwirkung ist kein Signifikanzwert etc angegeben. Nehme ich dann die Werte von der ANOVA ohne bootstrapping?
Liebe Grüße,
Martina
Liebe Martina,
ja, beim Bootstrapping werden keine Tests berechnet, keine Signifikanzen und keine Effektstärken angegeben. Dafür müssen Sie die Ausgabe der „normalen“ ANOVA verwenden. Das Bootstrapping können Sie aber gut verwenden, wenn Sie an den Post-Hoc Vergleichen interessiert sind oder zur Beschreibung der Unterschiede mit den Konfidenzintervallen.
Schöne Grüße
Daniela Keller
Hallo Frau Keller,
ich habe eine Variable x1, bestehend aus lauter Prozentwerten, ebenso wie die Variable x2. Den Einfluss dieser beiden Variablen auf eine dritte Variable y möchte ich untersuchen. Allerdings sind die Werte von y dichotom – Nullen & Einsen. Wie gehe ich dabei vor? Genauso wie bei einer Regressionsanalyse, bei der die Variable y aus „normalen“ Werten besteht? Kann man in dieser Konstellation auch eine Varianzanalyse berechnen? -Das hat mir ein Kollege vorgeschlagen, aber ich kann mir bei diesen Daten gar nicht vorstellen, wie das funktionieren soll.
Vielen Grüße
Hanna
Liebe Hanna,
in dem Fall passt eine logistische Regression gut. Da haben Sie ein dichotomes Outcome (Y) und können den Einfluss von einem oder mehreren metrischen (oder auch andersartigen) Faktoren auf dieses Outcome überprüfen.
Herzliche Grüße
Daniela Keller
Vielen Dank für diesen interessanten Artikel.