Tutorial am Beispiel der Software MAXQDA
Dieser Beitrag präsentiert ein Software-Tutorial zu einer sehr strukturierten und wissenschaftlich sauberen Kategorisierung offener Fragen bzw. Freitextantworten zu Mehrfachantwortensets. Im Fokus stehen daher die „Klickwege“ zur Umsetzung in der Computersoftware.
Leider bieten weder Statistik- (SPPS, Stata, R etc.) noch Tabellenkalkulationsprogramme (Excel, Calc etc.) Funktionen, die auf diesen Prozess ausgelegt sind. So wird die Kategorisierung meist über Workarounds erreicht, die das Vorgehen jedoch unstrukturierter und unübersichtlicher machen, worunter auch die Güte der Ergebnisse dieses Schrittes leiden kann und – vermutlich auch in den allermeisten Fällen ein Stück weit – leiden wird. Das saubere und transparente Kategorisieren ist jedoch mit einer QDA-Software wie dem Programm MAXQDA möglich, die auf die Auswertung qualitativer Daten ausgelegt ist.
Der Beitrag ist daher nicht nur eine Anleitung zur Umsetzung in MAXQDA, sondern gleichzeitig ein Aufruf, Kategorisierungen von Daten auf einem strukturierteren und transparenteren Niveau durchzuführen.
Damit ergänzt dieser Beitrag den des letzten Monats, in dem die methodische und methoden-praktische Dimensionen dieses Themas im Zentrum standen. Er bietet einen guten Einstieg, bevor die computergestützte Umsetzung vertieft wird:
Zusätzlich passt dieses YouTube-Video zum Thema Survey-Daten – Offene Antworten codieren & quantifizieren mit MAXQDA 2020 inhaltlich gut: https://www.youtube.com/watch?v=HTeHnQIuNEA
Ein YouTube-Video zur Verwendung von Mehrfachantwortensets mit SPSS findest Du hier: https://www.youtube.com/watch?v=gDdIseEyD-0
QDA-Software und MAXQDA – Was ist das?
Die Gruppe der QDA- oder CAQDA-Softwares (computer assisted/aided qualitative data analysis) kann sehr didaktisch-simplifiziert als das qualitative Pendant zu Statistik-Softwares bezeichnet werden. Diese Programme werden vor allem, aber nicht ausschließlich für die kategorien-, d.h. codebasierte qualitative oder quantifizierende Auswertung qualitativer Daten verwendet. Analog zu Variablen repräsentieren Kategorien (Codes) verschiedene Arten von Informationen (im weitesten Sinne des Wortes), die i.d.R. jedoch nicht aus Zahlen, sondern aus Text-, Bild-, Audio- oder Video-Segmenten bestehen. Die Software bietet zwar auch automatisierte Funktionen, unterstützt aber vor allem die interpretative „Handarbeit“ der Forschenden. MAXQDA gehört zu den internationalen Big Three der QDA-Programme, ist im deutschsprachigen Raum die mit Abstand verbreitetste Software (viele Hochschulen sind mit Campus-Lizenzen ausgestattet) und zudem Vorreiter für die Umsetzung von Mixed Methods.
Unter anderem bietet MAXQDA auch eigene Tools, die den Import, die Kategorisierung und Quantifizierung sowie den anschließenden Export von Umfrage-Daten ermöglichen. Die Software bietet aber nicht nur eine Lösung, um offene Antworten in Mehrfachantwortensets zu überführen, sondern kann auch für qualitative, statistische und Mixed-Methods-Analysen herangezogen werden.
Phase I: Daten importieren
- Vorbereitung: Exportiere die Survey-Datenmatrix als Excel-Datei. Praktisch ist dabei, dass statt der Werte direkt die Wertelabel eingefügt werden. Außerdem sollten kurze Variablenkürzel in den Spaltenköpfen durch verständliche Label ersetzt werden.
- Wähle in MAXQDA die zu importierenden Survey-Daten aus (Import Menüband > Survey-Daten > Daten aus Excel-Tabelle importieren).
Wenn du mit SurveyMonkey arbeitest, kannst du die Daten auch direkt vom Server importieren.
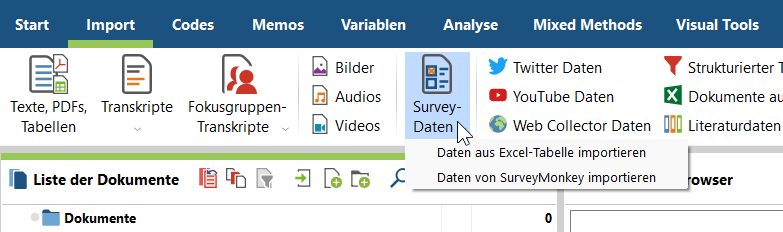
3. Lege fest, was MAXQDA auf Grundlage der Daten kreieren soll:
- Option 1 – rein statistische Analyse:Zur Kategorisierung und Quantifizierung der Freitextantworten für die anschließende statistische Analyse sind folgende Einstellungen sinnvoll:
-
- Im Dropdown-Menü „… die Dokumentgruppe?“ muss keine Auswahl getroffen werden.
- Im Dropdown-Menü „…den Dokumentnamen?“ muss die Fallnummer-Spalte ausgewählt werden, falls diese nicht automatisch erkannt wird (MAXQDA geht von der ersten Spalte aus).
- In der Liste sind alle Variablen des Datensatzes zu sehen. Wähle aus, dass diese auch in MAXQDA vollständig als Variablen erzeugt und die Variablen der offenen Fragen (in diesem Bsp.: Größte Weltprobleme) zusätzlich als Codes generiert werden.
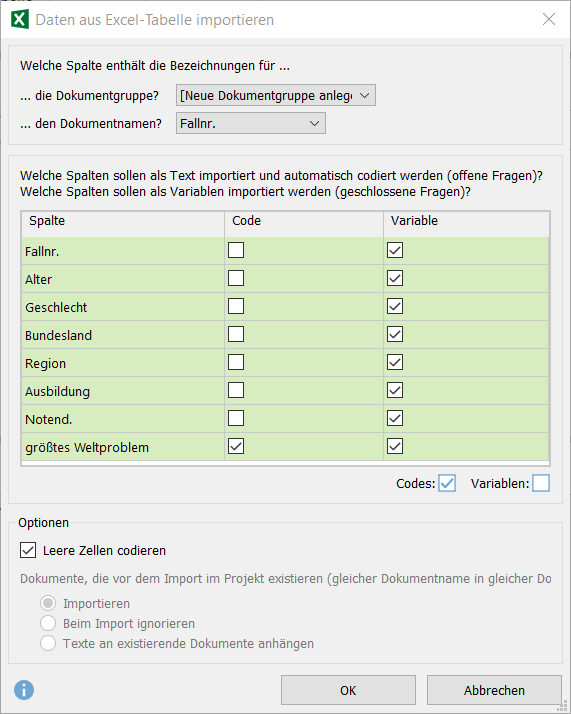
b. Option 2 – Mixed-Methods- bzw. teils qualitative Analyse:
Sollen auch qualitative Analysen, Worthäufigkeits- oder Wortkombinationsanalysen durchgeführt und diese mit den statistischen Daten in Beziehung gesetzt werden (Mixed Methods), dann sind folgende Einstellungen die beste Lösung
- Im Dropdown-Menü „… die Dokumentgruppe?“ kann die Variable ausgewählt werden, die am wichtigsten für Gruppenvergleiche ist. Dadurch werden die Fälle zu Gruppen gebündelt (in diesem Bsp.: nach Geschlechtern), wodurch sie schnell verglichen werden können.
- Im Dropdown-Menü „…den Dokumentnamen?“ muss die Fallnummer-Spalte ausgewählt werden, falls diese nicht automatisch erkannt wird (MAXQDA geht von der ersten Spalte aus).
- In der Liste sind alle Variablen des Datensatzes zu sehen. Wähle aus, dass alle Zeilen als Variablen und Codes in MAXQDA erzeugt werden. Dadurch sind die Informationen zwar doppelt – in einer für die qualitative sowie einer für die quantitative Forschung typischen Weise – im Projekt enthalten, aber du hast auch jederzeit die freie Wahl zwischen statistischen, qualitativen, linguistisch-wortbasierten und Mixed-Methods-Analysefunktionen.
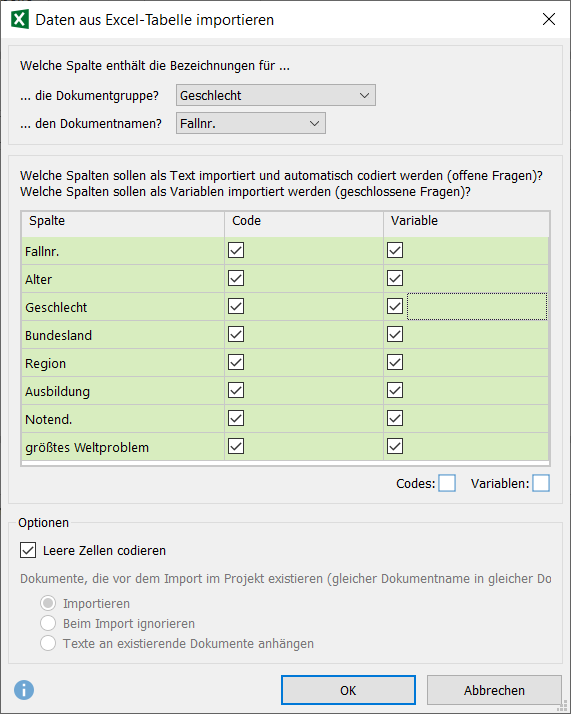
4. Prüfe in der Spalte Ziel, ob MAXQDA die Variablen-Typen korrekt identifiziert hat.
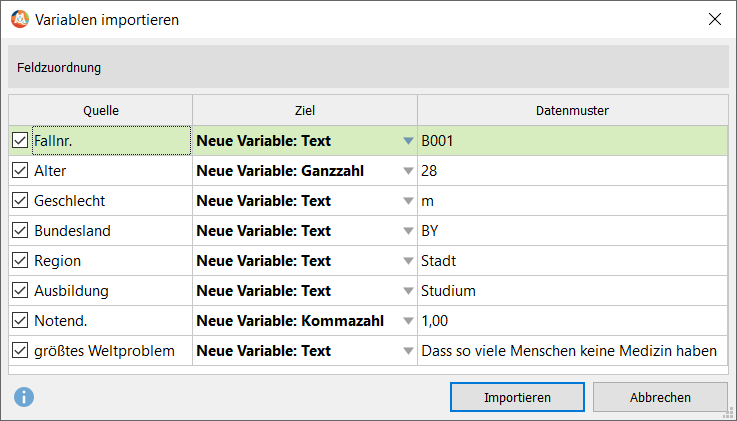
Exkurs: Ein Blick auf die Ergebnisse des Imports
- In der Liste der Dokumente (oben links) wird jeder Fall als ein Textdokument dargestellt. Wurde beim Import eine Variable zur Erzeugung von Dokumentgruppen gewählt (Option 2; vgl. letzter Schritt), werden die Fälle in blaue Ordner einsortiert (in diesem Bsp.: nach Geschlechtern). In der Liste der Codes (unten links) werden alle aus Variablen transformierte Codes dargestellt, wie zuvor in Option 2 ausgewählt. Im Dokument-Browser (rechts) ist der gerade geöffnete Fall (B001) als Textdokument zu sehen; jeder Wert wird in einer Zeile dargestellt, die mit dem entsprechenden Code codiert wurden (zu sehen an den Klammern rechts vom Text). Wurde im letzten Schritt Option 1 gewählt, wären in der Liste der Codes ausschließlich „Größte Weltprobleme“ und im Dokument-Browser ausschließlich diese Freitextantwort zu sehen.
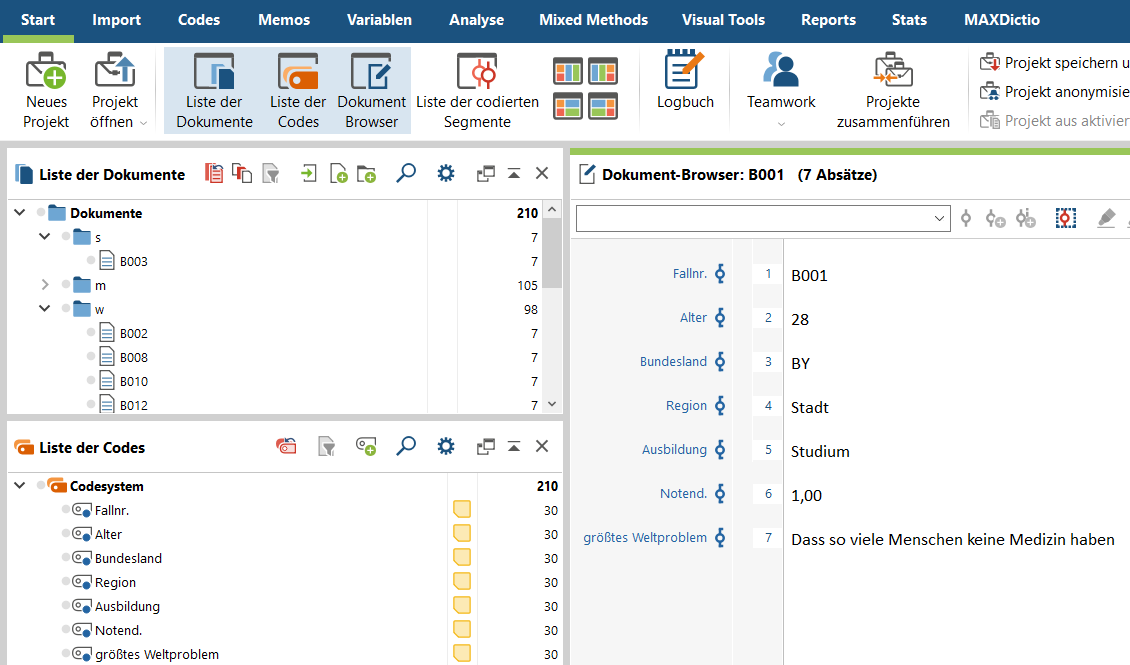
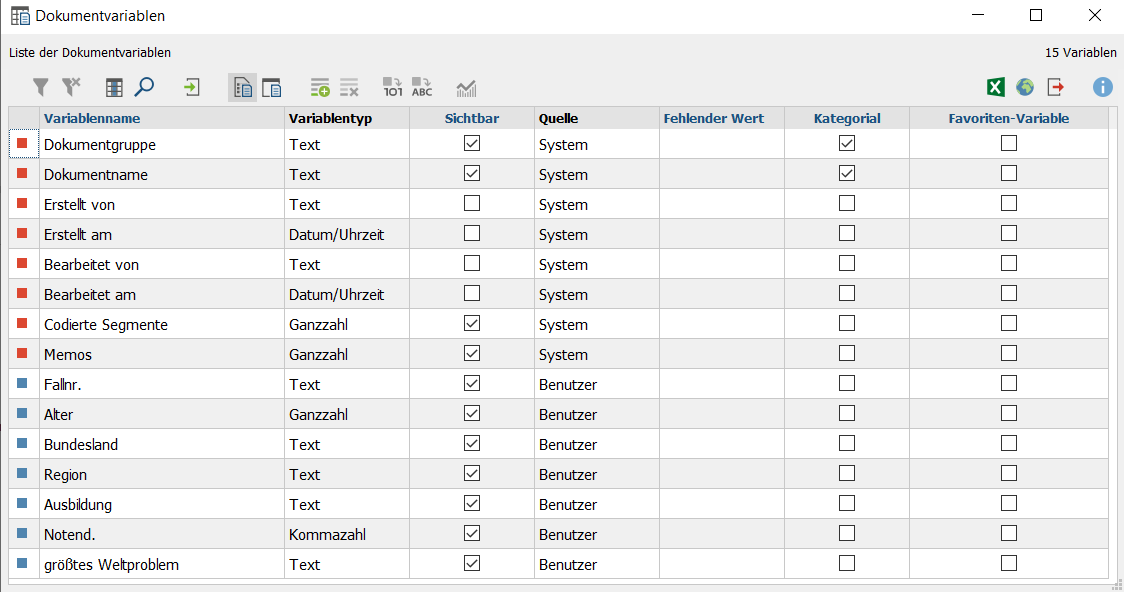
2. Betrachte den Variablen- und Dateneditor (Variablen Menüband > Liste der Dokumentvariablen / Dateneditor für Dokumentvariablen).

Variableneditor: Die blauen Variablen wurden durch den Import erzeugt und entsprechen denen des importierten Datensatzes; die roten Variablen werden immer automatisch von MAXQDA erzeugt und können ignoriert werden.
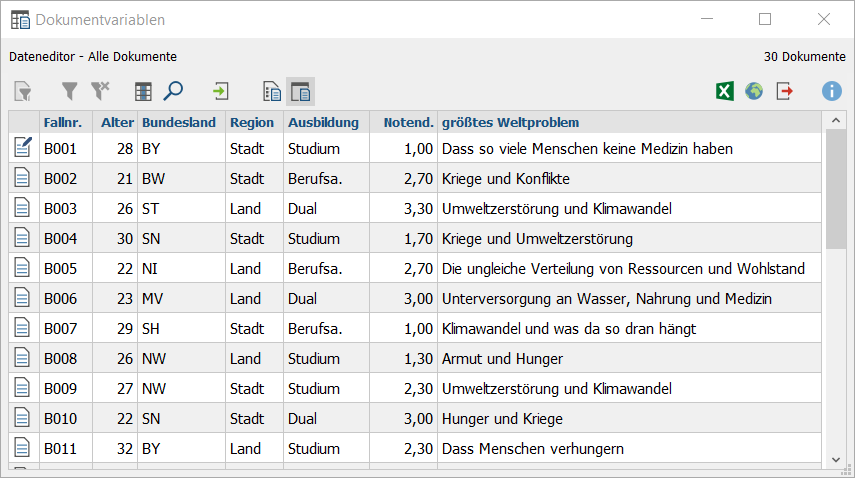
Dateneditor: Die Ansicht ist inhaltsidentisch mit dem importierten Datensatz.
Phase II: Daten kategorisieren
Wie bereits im letzten Blog-Beitrag dargestellt, gibt es mehrere Möglichkeiten, die Daten zu kategorisieren (zu codieren). Zur Wiederholung:
- Deduktiv vs. induktiv: Die Daten können mit einem aus der Theorie stammenden, als Codesystem erzeugten Analyseraster kategorisiert werden – deduktiv. Oder die Daten können analytisch betrachtet werden, um aus ihnen eine sinnvolle Gruppierung bzw. Ausdifferenzierung abzuleiten – induktiv.
- Auto-Codierung vs. manuell-interpretatives Codieren: Die Daten können durch Lesen, Interpretieren und händisches Zuordnen zu Codes kategorisiert oder anhand von Wortkatalogen (Liste mit Suchbegriffen als Indikatoren für Themen) automatisch kategorisiert werden.
Daraus ergeben sich vier Optionen, deren jeweilige Umsetzung im Folgenden erklärt wird:
- Interpretatives Kategorisieren mit deduktiven Codes
- Interpretatives Kategorisieren mit induktiven Codes
- Autocodieren mit deduktiven Codes
- Autocodieren mit induktiven Codes
Option 1: Interpretatives Kategorisieren mit deduktiven Codes
Wenn deduktive Codes zur Kategorisierung feststehen, sollten diese bereits in der Datenerhebung berücksichtigt werden. Dazu würde im Fragenbogen ein Mehrfachantwortenset statt einer Freitextantwort eingebaut werden; die Teilnehmenden würden sich selbst zuordnen, statt dass ihre offenen Antworten zugeordnet, also kategorisiert werden müssen. Diese Option ist daher im Rahmen der Analyse von Umfragen nur relevant, wenn die Kategorisierung erst nach Beginn der Datenerhebung beschlossen wurde oder bewusst offen und daher induktiv gestaltet werden soll. Sie kann jedoch auch immer dann relevant sein, wenn es nicht Survey-, sondern andere qualitative Daten sind, die quantifiziert werden sollen, z.B. wenn Zeitungsartikel thematisch kategorisiert werden, um die Häufigkeit von Themen auszuzählen.
- Klicke in der Liste der Codes auf das Plus-Symbol in der Zeile des Codes, der die offene Frage repräsentiert.
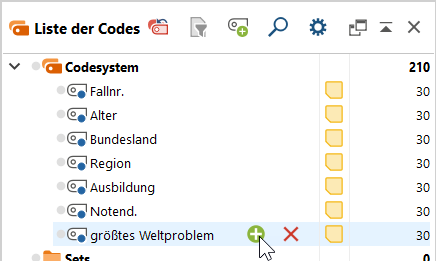
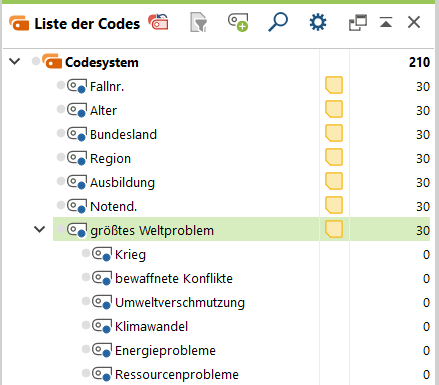
2. Erzeuge nach und nach die theoriegeleiteten Subcodes; klicke dazu auf [Weiterer Code].

Das Ergebnis:
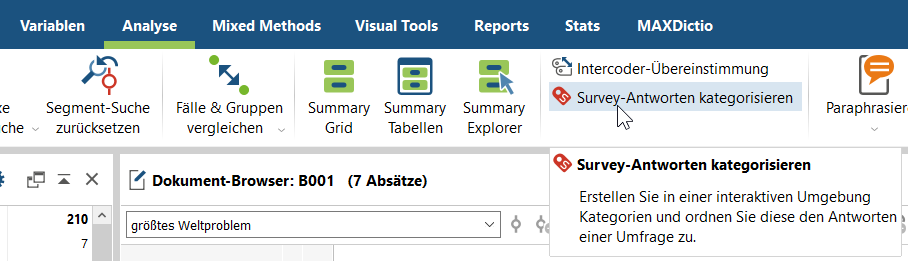
3. Kategorisiere die Daten (Analyse Menüband > Survey-Daten kategorisieren).
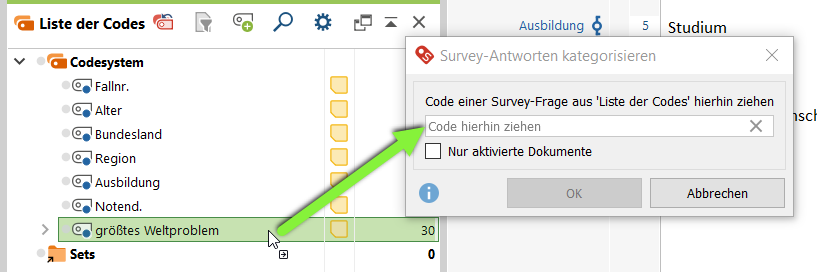
Ziehe den Code, der die zu kategorisierenden Freitextantworten repräsentiert, per Drag&Drop von der Liste der Codes ins Fenster Survey-Antworten kategorisieren.
Sichte die Antworten und ziehe nach und nach die Antwort-Zeilen (rechts) auf die entsprechenden Codes (links):
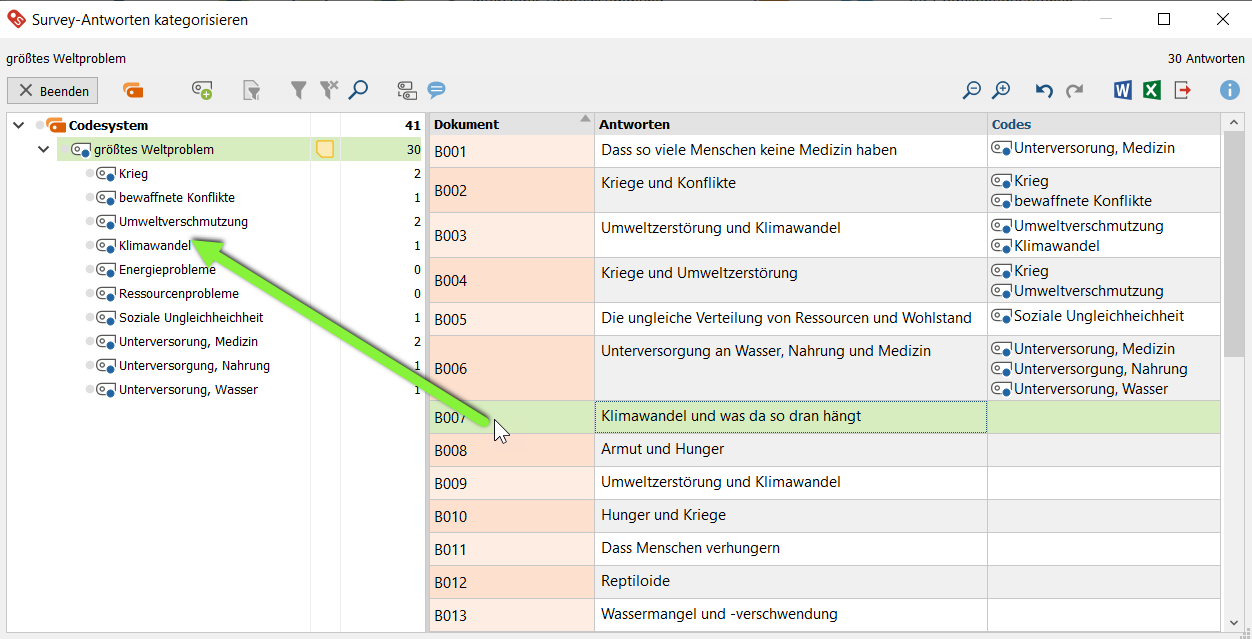
Option 2: Interpretatives Kategorisieren mit induktiven Codes
- Ziehe den Code, der die zu kategorisierenden Freitextantworten repräsentiert, per Drag&Drop von der Liste der Codes ins Fenster Survey-Antworten kategorisieren.
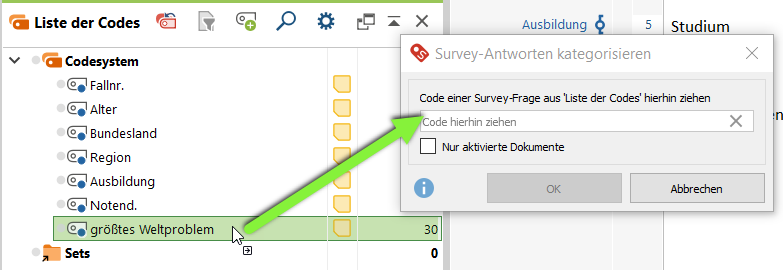
2. Erzeuge eine Kategorie auf Basis der ersten Antwort (Rechtsklick auf Antwort > Neuen Code erstellen und Zuordnen).
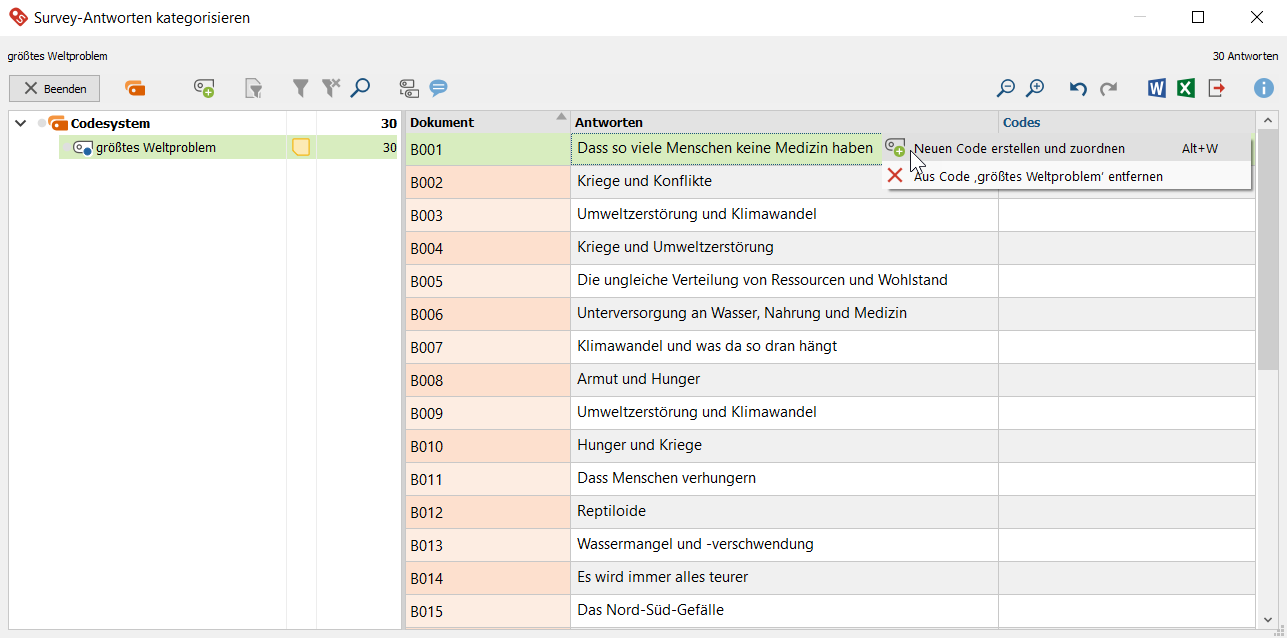
Die Wahl des passenden Labels (Kategorienbezeichnung) für induktive Codes kann anfangs schwerfallen und lässt sich besser treffen, sobald einem Code mehrere Antworten zugeordnet wurden. Daher empfiehlt es sich, beim Erzeugen eines Codes nicht zu viel Zeit in Überlegungen zu einem passenden Label zu investieren, dieses stattdessen als provisorisch anzusehen, im späteren Verlauf des Codier-Prozesses weiterzuentwickeln und früher oder später zu finalisieren. Überlegungen zur Code-Entwicklung können im Code-Memo notiert werden. Das Memo wird als gelbes Post-it-Symbol neben dem Code dargestellt und kann per Doppelklick geöffnet werden. In diesem Beispiel ist mit Blick auf den zu formulierenden Ergebnisbericht, konkret z.B. auf die Balkenbeschriftungen in einem Diagramm, jedoch bereits jetzt klar, dass die Aussage „Dass so viele Menschen keine Medizin haben“ mit dem theoretischer klingenden Label „Unterversorgung, Medizin“ kategorisiert werden kann.
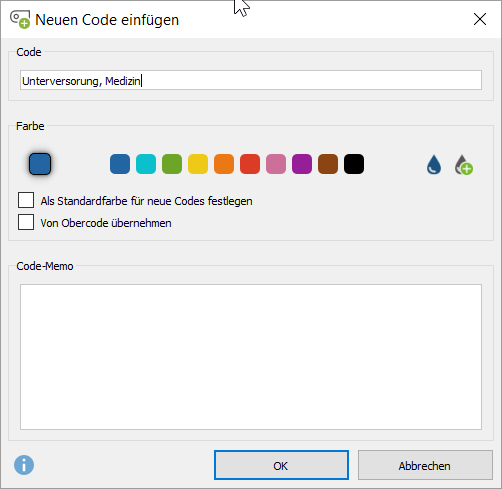
Das Ergebnis:
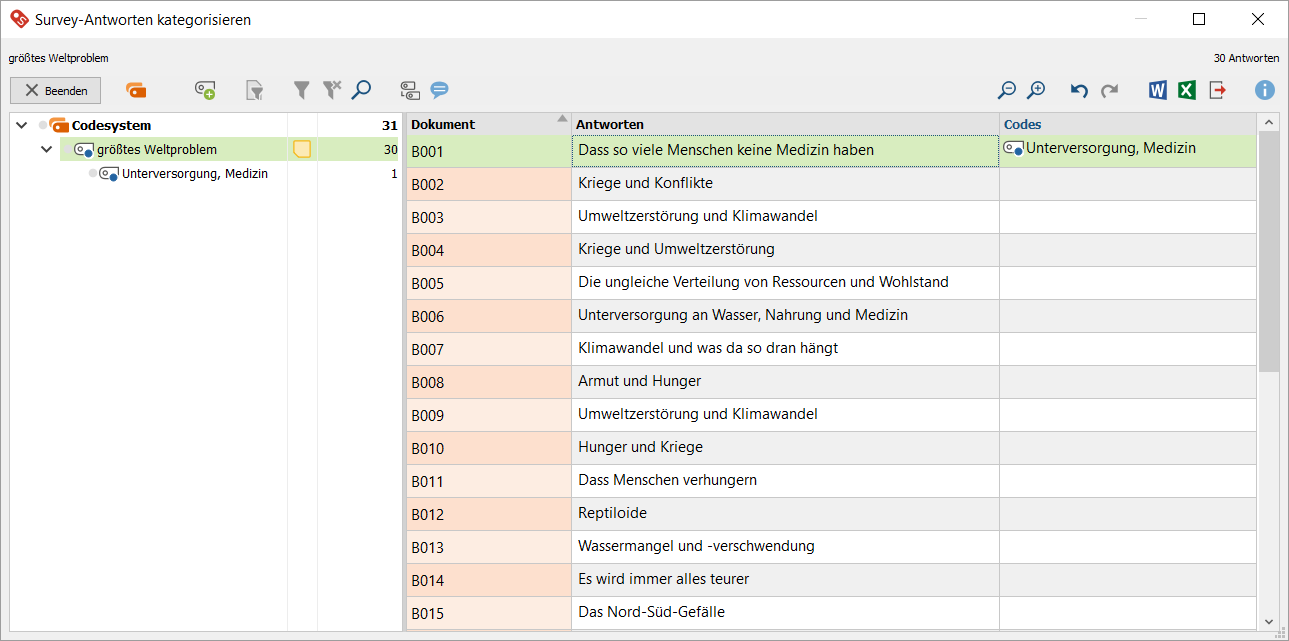
3. Nach und nach werden die Antworten kategorisiert und dabei neue Codes erzeugt. Existiert bereits ein Code für eine Antwort, muss er nicht erneut erzeugt werden; ziehe die Antwort-Zeile (rechts) einfach auf die entsprechenden Codes (links):
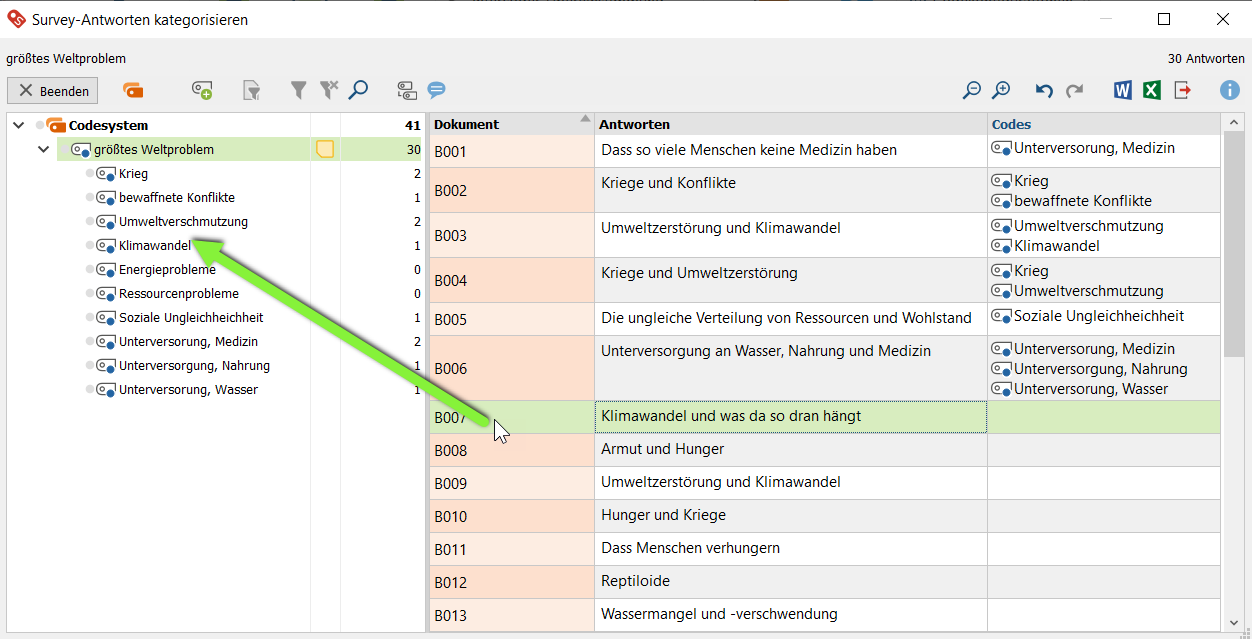
Option 3: Autocodieren mit deduktiven Codes
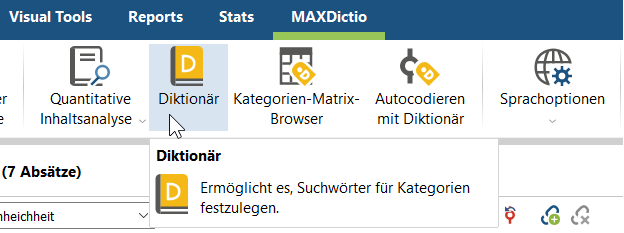
- Stelle einen Wortkatalog auf (MAXDictio Menüband > Diktionär):
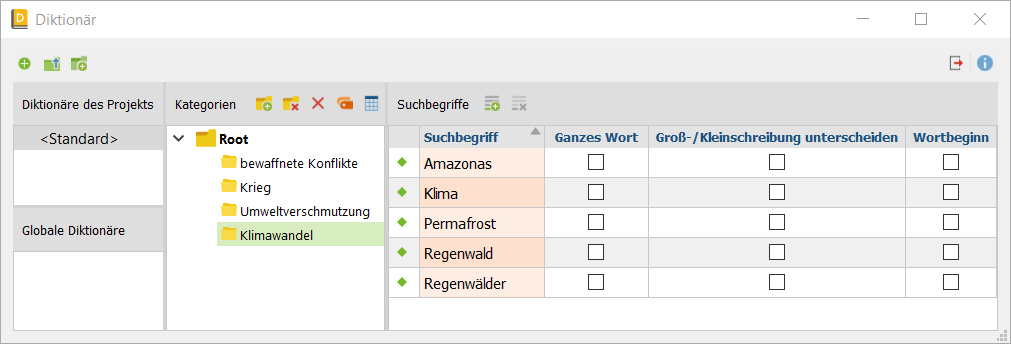
2. Erzeuge die deduktiven Kategorien (Icon: gelber Ordner mit grünem Plus-Kreis) und trage pro Kategorie die Suchbegriffe oder Suchphrasen (Icon: Liste mit grünem Plus-Kreis) ein, anhand derer sie identifiziert werden kann. Es ist auch möglich, hierarchische Kategoriensysteme zu konstruieren, bei denen Ober- und Unterkategorien wie Ordner ineinander verschachtelt sind. In diesem Beispiel wurde davon jedoch abgesehen. Hier sind die Suchbegriffe der Kategorie „Klimawandel“ zu sehen:
3. Starte die Autocodierung (MAXDictio Menüband > Autocodierung mit Diktionär).
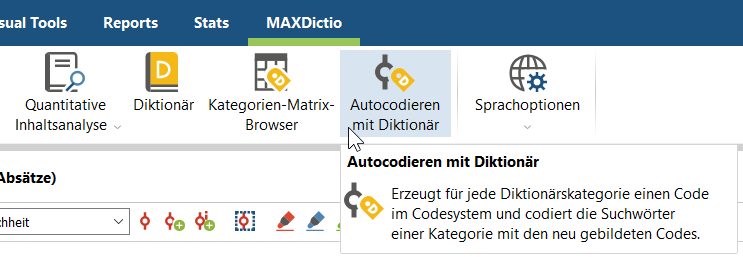
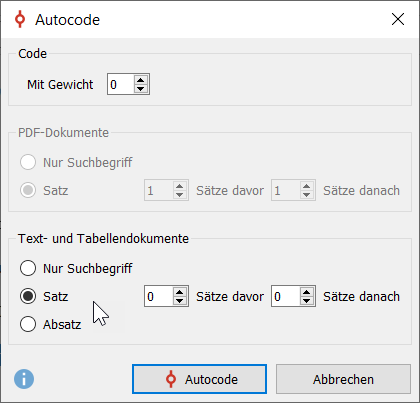
4. Bestimme die Größe des zu codierenden Segments, z.B. nur die Suchbegriffe, den ganzen Satz oder Absatz.
Für die rein statistische Analyse ist die Auswahl egal, da nur mit den Codierhäufigkeiten (Anzahl, wie oft bzw. in wie vielen Dokumenten ein Code vergeben wurde) weitergearbeitet wird. Sollen die Antworten jedoch auch qualitativ-interpretativ analysiert werden, sollte eher ein ganzer Satz oder sogar die ganze Antwort codiert werden, so dass das codierte Segment verständlich bleibt.
Option 4: Autocodieren mit induktiven Codes
Die vermutlich untypischste Kombination ist das automatische Codieren mit induktiven Codes. MAXQDA bietet jedoch gute Tools, die das Potential haben, dieser vierten, theoretisch denkbaren Option mehr Gewicht in der Forschungspraxis zu verleihen: Die Antworten können per Worthäufigkeits- oder Wortkombinationsanalyse exploriert werden. Dieser Schritt ist zwar interpretativ, also nicht automatisiert, fällt jedoch kürzer aus als bei Option 2. Auf dieser Basis können Kategorien und ihre Indikatoren, die Suchbegriffe, zum Start einer Autocodierung genutzt werden.
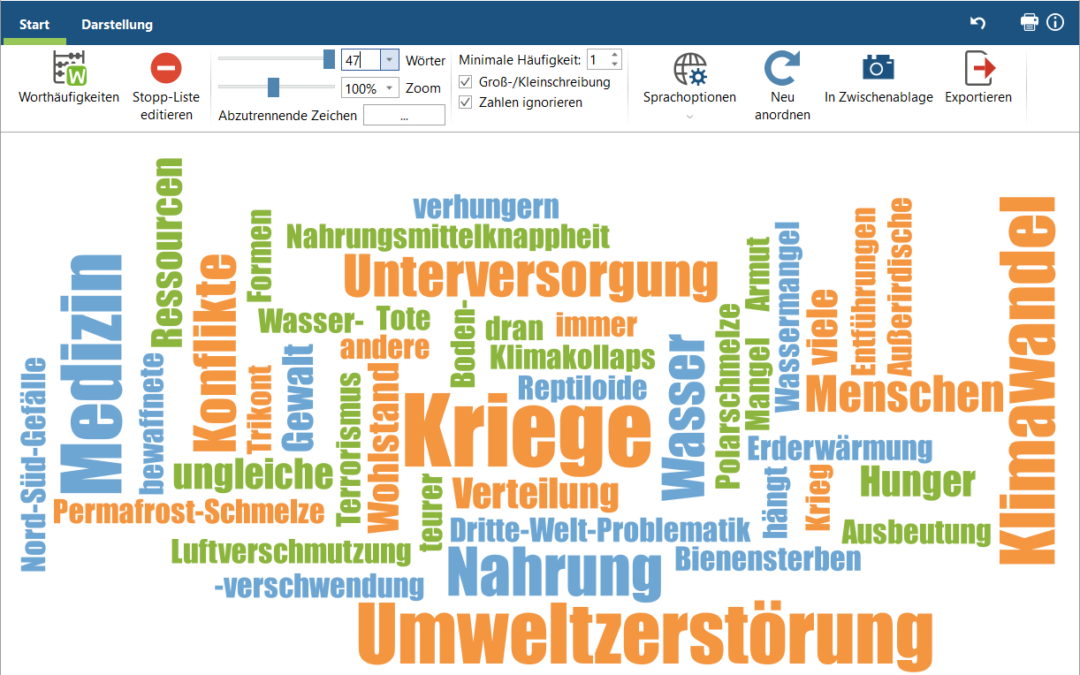
- Lasse dir alle Antworten auf eine offene Frage anzeigen. Klicke dazu in der Liste der Dokumente auf das Ordner-Symbol der obersten Ebene Dokumente sowie in der Liste der Codes auf das Symbol des gewünschten Codes; sie werden rot.
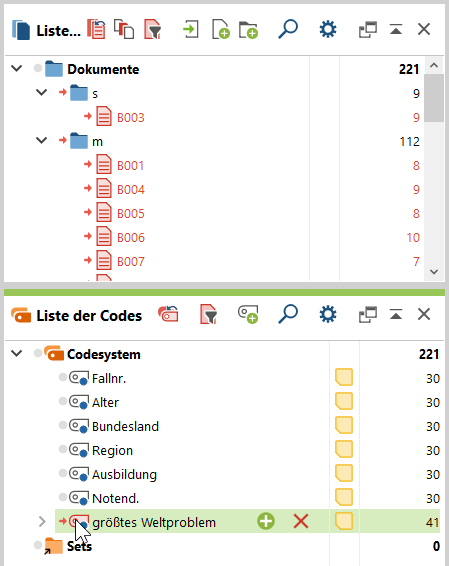
2. Die Antworten werden in der Liste der codierten Segmente dargestellt (unten rechts). Klicke dazu in der Symbolleiste dieser Liste auf Wortwolke.
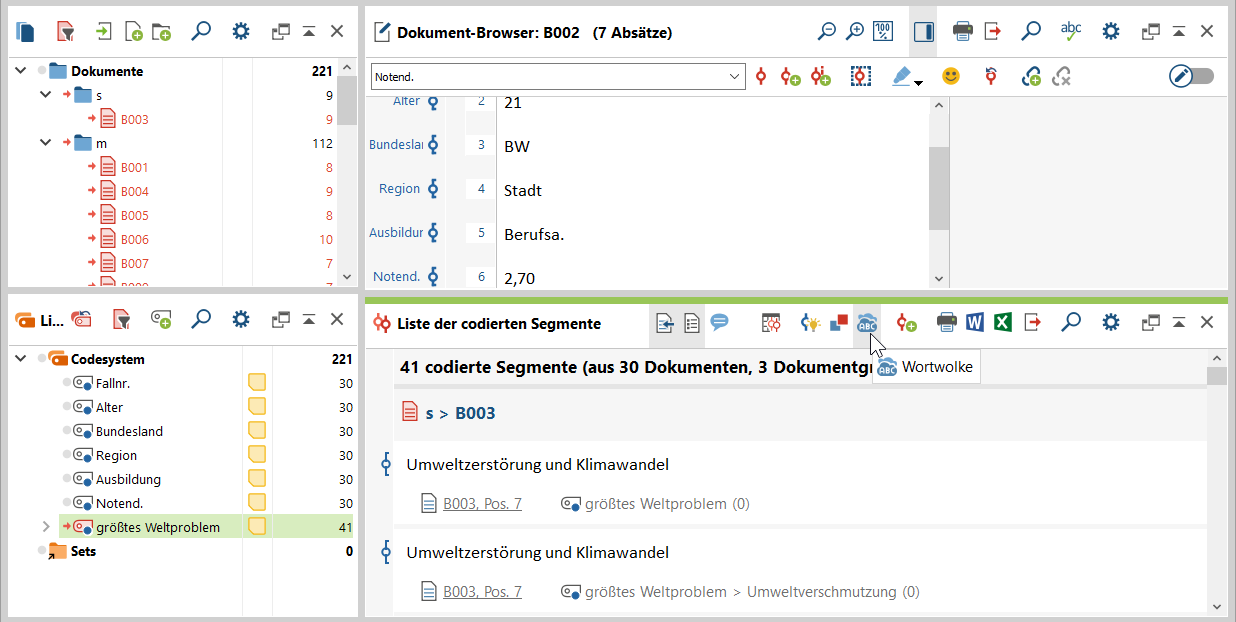
3. Die Wortwolke basiert auf einer Worthäufigkeitszählung und umfasst zunächst auch Worte, die für die Kategorienbildung nicht relevant sind. Z.B. wird das Wort „und“ am häufigsten verwendet und steht daher in besonders großer Schrift im Zentrum der Wolke. In den meisten Fällen sollten irrelevante Worte von der Analyse ausgeschlossen werden. Dabei können einzelne Worte (Rechtsklick auf das Wort > In die Stopp-Liste) oder eine vorher aufgesetzte Liste von Worten (Stopp-Liste editieren) ignoriert werden.
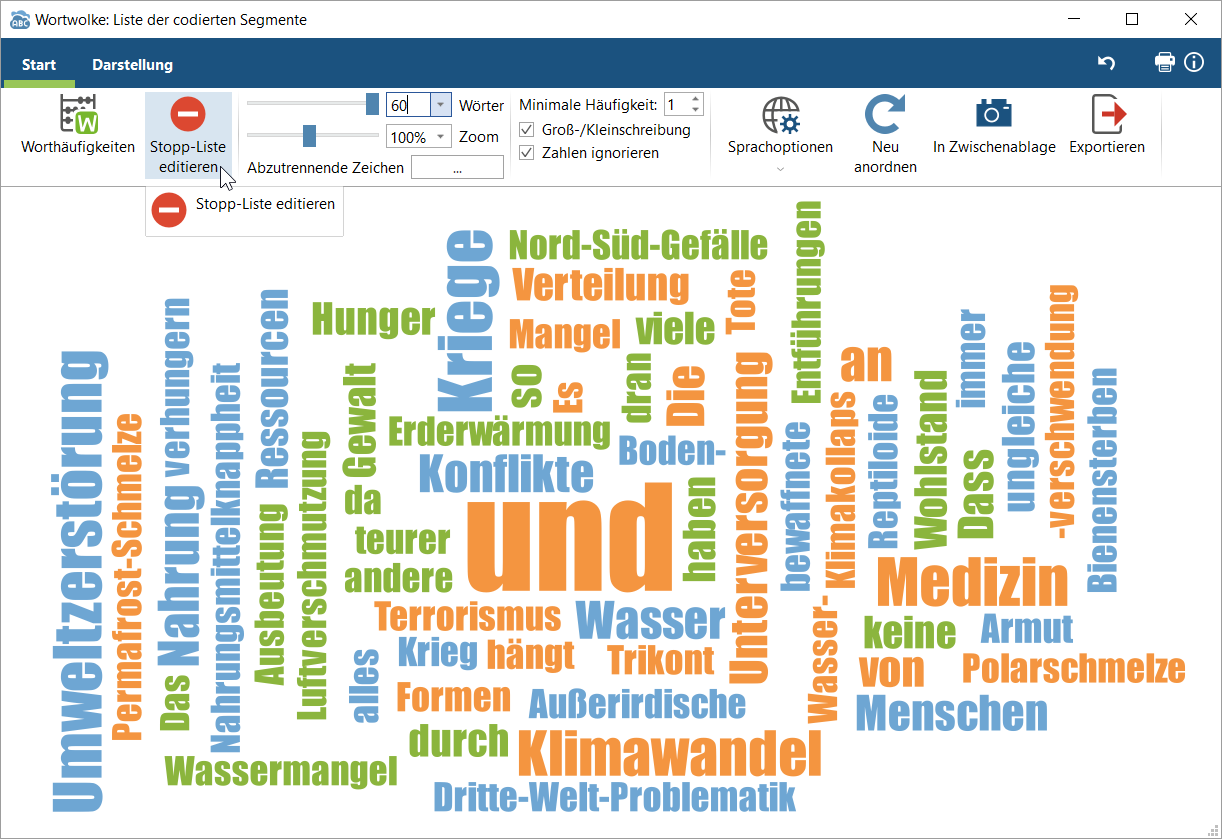
4. Oft genügt es, eine der auf der MAXQDA-Webseite bereitgestellte Listen herunterzuladen (Deutsche Stopplisten herunterladen | Englische Stopplisten herunterladen), in denen u.a. alle Artikel und Pronomen enthalten sind, und diese anschließend zu importieren (zweites Icon: Liste importieren).

5. In diesem Beispielprojekt hat die Stopp-Liste der MAXQDA-Webseite perfekte Ergebnisse geliefert. Nahezu alle übriggebliebenen Begriffe sind für die Erzeugung der Kategorien relevant. Sichte nach und nach die Fundstellen der einzelnen Worte (Doppelklick auf das Wort).
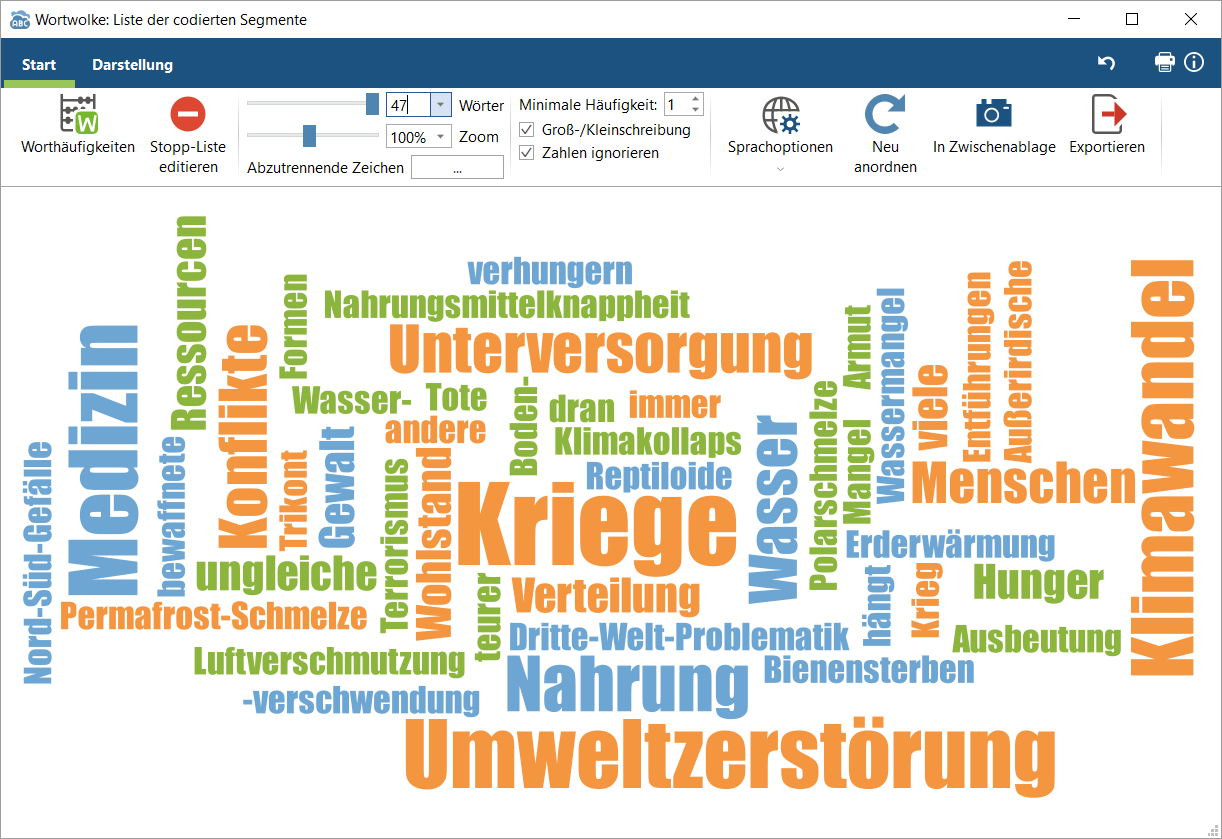
6. Die Fundstellen (des Wortes „Krieg“) werden zeilenweise dargestellt. Starte die Autocodierung der Daten (Suchergebnisse mit neuem Code autocodieren).
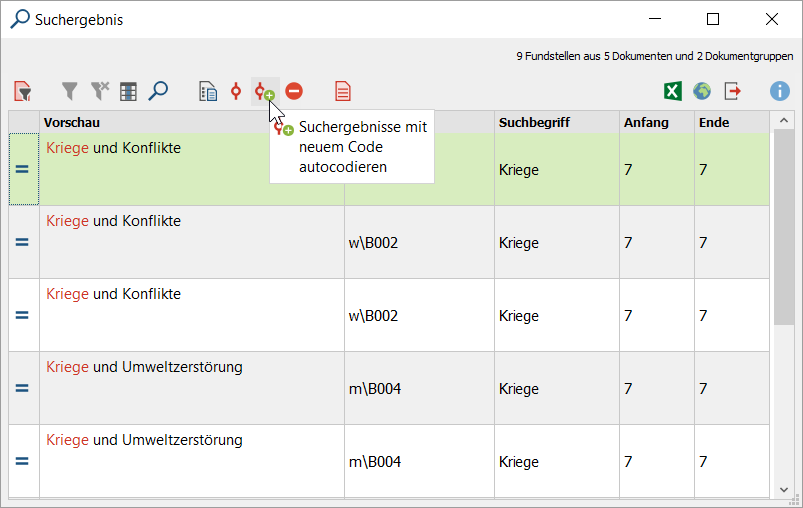
7. Erzeuge einen Code für Antworten dieser Art.
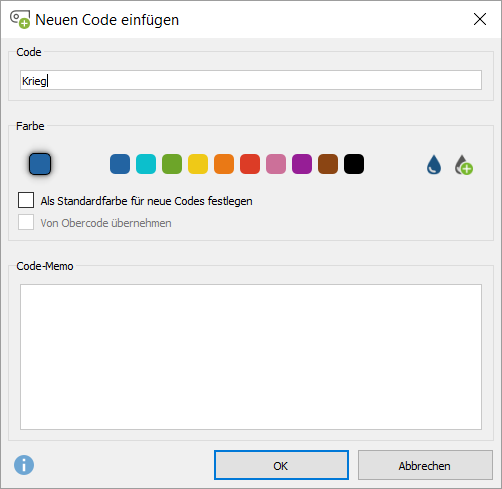
8. Bestimme die Größe des zu codierenden Segments, z.B. nur die Suchbegriffe, den ganzen Satz oder Absatz.
Für die rein statistische Analyse ist die Auswahl egal, da nur mit den Codierhäufigkeiten (Anzahl, wie oft bzw. in wie vielen Dokumenten ein Code vergeben wurde) weitergearbeitet wird. Sollen die Antworten jedoch auch qualitativ-interpretativ analysiert werden, sollte eher ein ganzer Satz oder sogar die ganze Antwort codiert werden, so dass das codierte Segment verständlich bleibt.
9. Das in den Schritten 1-8 beschrieben Vorgehen kann übrigens nicht nur mit einzelnen Suchbegriffen, sondern auch mit Wortkombinationen umgesetzt werden (MAXDictio Menüband > Wortkombinationen).
Phase III: Kategorisierung quantifizieren
Unabhängig von der in Phase II gewählten Option zur Kategorisierung der Daten kann das Ergebnis dieses Prozesses jetzt quantifiziert werden. Das bedeutet, dass die Codes in Variablen und die Codierhäufigkeiten in Werte transformiert werden. Das Ergebnis ist die Erweiterung der ursprünglichen Variablen im quantitativen Datensatz um ein Mehrfachantwortenset.
- Wähle die Codes aus, die quantifiziert werden sollen. Klicke dazu auf die Symbole der gewünschten Codes; sie werden rot.
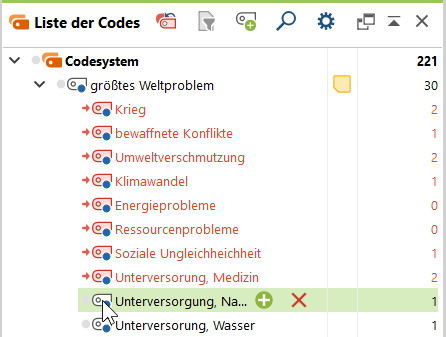
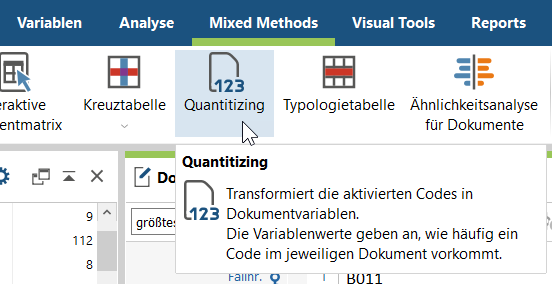
2. Starte das Quantifizieren (Mixed Methods Menüband > Quantitizing).
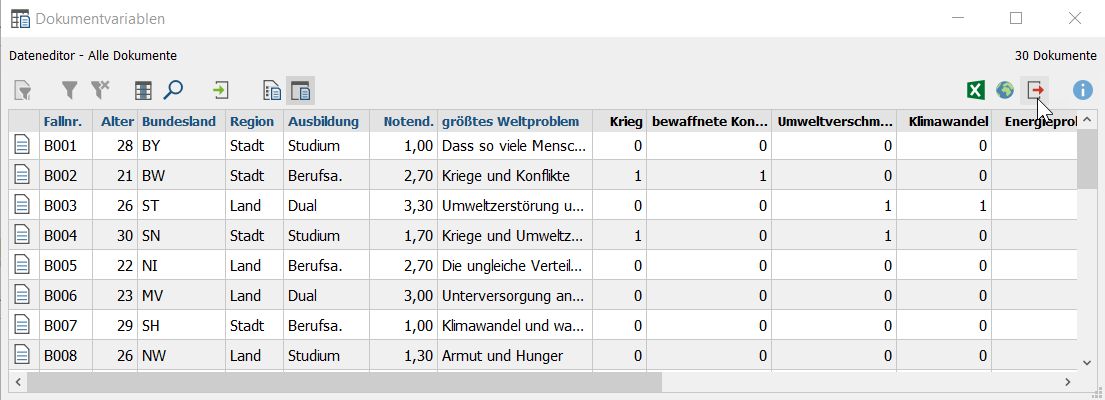
3. Anschließend öffnet sich automatisch der Dateneditor, in dem rechts von der Variable „größtes Weltproblem“ das neu erzeugte Mehrfachantwortenset zu sehen ist. Wurde MAXQDA ausschließlich für das Kategorisieren genutzt und soll die Analyse in einer Statistik-Software fortgesetzt werden, kann die Datenmatrix im Excel- und SPSS-Format exportiert werden (rechts, Icon am Cursor).
Vorteile von QDA-Software für Kategorisieren
Um eine offene Frage zu kategorisieren, also in ein Mehrfachantwortenset zu überführen, ist technisch gesehen lediglich eine Tabelle notwendig. In der ersten Spalte ist die offene Antwort zu sehen; weitere Spalten bilden die Kategorien ab, denen die Antworten zugewiesen werden. Dazu werden in den Zellen die Werte 1 und 0 eingetragen, je nachdem, ob bei einer Antwort eine Kategorie vorkommt oder nicht. Dementsprechend kann die Arbeit direkt in einer Statistik-Software erledigt werden (z.B. SPSS, Stata oder R). Oft bietet es sich jedoch an, die Variablen-Spalte der offenen Frage in eine Tabellenkalkulations-Software (z.B. Excel oder Calc) zu kopieren, dort zu kategorisieren und anschließend wieder in die Statistik-Software einzufügen. Durch die Extraktion des für diesen Schritt relevanten Teils des Datensatzes wird die Arbeitsumgebung, d.h. die Tabelle übersichtlicher.
Beide Optionen – Statistik- und Tabellenkalkulations-Software – sind jedoch keine optimalen Lösungen für den Prozess des Kategorisierens selbst, insbesondere dann nicht, wenn die Codes induktiv erzeugt werden oder wenn die Codierung automatisiert geschehen soll.
Die induktive Codeerzeugung ist ein iterativer, zirkulärer Prozess, der gerade am Anfang mit Revisionen wie etwa dem Umbenennen von Codelabeln oder der Festlegung von Grenzen zwischen einzelnen Codes verbunden ist und deshalb Flexibilität und Überschaubarkeit voraussetzt. MAXQDA bietet diese an, indem das Codesystem neben den Daten dargestellt wird. Das Umbenennen, Sortieren und Hierarchisieren sowie das Ausdifferenzieren in Subcode-Ebenen oder das erneute Bewerten einzelner Codier-Entscheidungen können in MAXQDA sehr einfach durch Klick, Doppelklick oder Drag&Drop realisiert werden.
Für die Autocodierung der Daten bietet MAXQDA mehrere Funktionen an (die wichtigsten wurden in Phase II gezeigt), für die weder Statistik- noch Tabellenprogramme eine alternative Lösung anbieten. Insofern ist eine QDA-Software mit Autocodier-Funktionen wie MAXQDA alternativlos im Vergleich dieser drei Gruppen.
Vorteile qualitativer und Mixed-Methods-Analysen
Weitere Vorteile der Verwendung von MAXQDA ergeben sich durch das große Spektrum an Analysefunktionen. MAXQDA kann nicht nur zur Kategorisierung und Quantifizierung, sondern auch für die Analyse selbst verwendet werden. Das größte Paket der Software (MAXQDA Analytics Pro) beinhaltet qualitative, quantifizierende, wortbasierte, Mixed-Methods- und rein statistische Analysefunktionen. Dadurch können die Variablen statistisch und die Freitextantworten qualitativ ausgewertet, aber auch in Zusammenhang zueinander gesetzt werden (Mixed Methods).
An dieser Stelle sei darauf hingewiesen, dass es sich oftmals lohnen kann, nicht nur statistisch mit dem Mehrfachantwortenset zu arbeiten, sondern die Antworten auch einer zumindest oberflächlichen qualitativen Analyse zu unterziehen oder quantitative und qualitative Daten in der Analyse in Beziehung zu setzen.
Rädiker und Kuckartz (2020) vertiefen in ihrem Guide zur Analyse von Survey-Fragen nicht nur viele Überlegungen dieses Blog-Beitrags, sondern gehen über diesen hinaus: Sie zeigen die Vorteile der qualitativen und integrierten Analyse auf und beschreiben außerdem anhand von konkreten Beispielen die Möglichkeiten von MAXQDA: u.a. die interpretative Analyse der Antworten, Häufigkeitsdiagramme, Zusammenhangs- und Kombinationsanalysen der Codes, Identifikation von Gruppen, Gruppenvergleiche sowie Statistik für qualitative Gruppen.
Dadurch wird der Guide zur perfekten Vertiefungsliteratur.
Literaturtipp

Rädiker, Stefan; Kuckartz, Udo (2020): Offene Survey-Fragen mit MAXQDA analysieren. Schritt für Schritt. Berlin: MAXQDA Press.
Kostenloser Download: https://www.maxqda-press.com/catalog/guides/maxqda-press-offene-survey-fragen-mit-maxqda-analysieren
Videotipps
Statistik und Mixed-Methods-Analysen mit MAXQDA Stats
https://www.youtube.com/watch?v=vBicU15p_ww
Mixed-Methods-Analyse mit MAXQDA 2020
https://www.youtube.com/watch?v=Yz0JXg7d-kc
Die 10 häufigsten Fehler bei Abschlussarbeiten mit SPSS und wie du sie vermeidest.
Hol dir jetzt die Liste für 0,- Euro und komm mit deiner Datenanalyse fehlerfrei und schnell voran!

Ich bin Diplom-Sozialwissenschaftler mit Zusatzqualifikation für Gender Studies, habe 2010-2015 in der Methodenlehre am Institut für Soziologie der Universität Hannover gearbeitet und mich 2015 hauptberuflich selbstständig gemacht. Unter dem Namen Methoden Coaching Morgenstern biete ich seither Dienstleistungen rund um qualitative Forschung und Mixed Methods an. Du kannst mich für individuelle oder gruppenspezifische Beratung, für Lehrveranstaltungen und für Auftragsforschung buchen. Außerdem bin ich Professional Trainer der QDA-Software (Qualitative Data Analysis) MAXQDA. Auf meinem YouTube-Kanal behandle ich methodische und praktische Fragen der qualitativen Forschung: http://youtube.methoden-coaching.de



