In diesem Beitrag wird eine praxisnahe Anleitung zur Kategorisierung offener Fragen bzw. Freitextantworten an die Hand gegeben. Dabei wird gezeigt, wie das Kategorisieren von offenen Antworten mithilfe einer computergestützten (quantitativen oder qualitativen) Inhaltsanalyse realisiert werden kann, etwa um Mehrfachantwortensets zu bilden oder generell die statistische oder optional auch die qualitative Analyse vorzubereiten.
Der vorliegende Beitrag setzt damit an einem früheren Blog-Beitrag an, in dem Theresa Loy verschiedene Varianten der Inhaltsanalyse auf der methodischen Ebene darstellt: die Qualitative Inhaltsanalyse nach Mayring, die Quantitative Inhaltsanalyse (nach Früh) und die als „Computergestützte Inhaltsanalyse“ bezeichnete vollautomatisierte Variante der Quantitativen Inhaltsanalyse (Loy 2015). Der Beitrag sei zur methodischen Vertiefung empfohlen.
Demgegenüber wird im vorliegenden Beitrag die praktische Umsetzung fokussiert. Während dieser Beitrag die allgemeine Umsetzung erklärt, wird ein weiterer Beitrag im November 2020 die computergestützte Umsetzung (sogenannte Klickwege) behandeln.
Verortung des Vorgehens
Bei dem hier vorgestellten Weg handelt sich um einen qualitativen Ausflug in einem eigentlich quantitativ-statistischen Prozess. Er ist für alle Projekte relevant, in denen neben standardisierten Items und nummerischen Daten auch qualitative Daten wie Text, Bild, Audio und Video ausgewertet werden. Die vermutlich mit Abstand verbreitetste Anwendung qualitativer Methoden in quantitativen Projekten finden Freitextantworten in Fragebögen. Sie gewinnen in vielen quantitativ orientierten Forschungsfeldern wie etwa der Markt- und Evaluationsforschung an Bedeutung, weil das Potential der Offenheit qualitativer Daten zunehmend genutzt wird, um subjektive Sichtweisen und Meinungen wie etwa Begründungen, Kritik und Verbesserungsvorschläge einzufangen. Das illustrieren beispielsweise Evaluationsbögen für Lehrveranstaltungen sehr gut, in denen es die Norm ist, neben der geschlossenen Frage „Wie bewerten Sie die Veranstaltung insgesamt?“ (standardisierte Antworten im Schulnotensystem) auch die offenen Fragen „Was fanden Sie besonders gut?“ und „… besonders schlecht?“ (Freitextantwort) zu stellen, um nicht nur zu erfahren, wie etwas bewertet wird, sondern auch, warum es so bewertet wird. Der hier als „qualitativer Ausflug“ bezeichnete Weg kann zur Kategorisierung und Quantifizierung der qualitativen Daten zur anschließenden statistischen Analyse führen oder noch einen weiteren qualitativen Schritt hinein in die Auswertung gehen, beispielsweise indem typische Antworten zur Illustration oder Begründungen zur Unterfütterung der quantitativen Ergebnisse ergänzt werden.
(Quantitative) Inhaltsanalyse und Qualitative Inhaltsanalyse
Die Inhaltsanalyse ist ein quantitatives Verfahren, das ursprünglich zur Untersuchung des Aufkommens von Themen in einer großen Anzahl von Zeitungsartikeln geschaffen wurde, seither viele methodische Weiterentwicklungen erfahren hat und sich großer Beliebtheit bei der Analyse von Texten insgesamt erfreut, darunter auch Freitextantworten auf offene Fragen. Dabei werden Suchbegriffe bestimmt, anhand derer die Themen im Text identifiziert werden können: Beispielsweise kann das Thema Umweltverschmutzung mit zusätzlichen Suchbegriffen wie Luft-, Boden- oder Wasserverschmutzung, eventuell auch mit Klimawandel, klimatischen Veränderungen, Permafrostboden etc. unterfüttert werden. Die Themen selbst werden als Schlagworte – sogenannte Kategorien oder Codes – erzeugt, die zusammen einen Schlagwortbaum – das sogenannte Kategorien- oder Codesystem – bilden. Die Texte (zum Beispiel ein ganzer Artikel oder eine ganze Freitextantwort) oder ihre Segmente (zum Beispiel Sätze oder Absätze), in denen ein anhand seiner Suchbegriffe identifiziertes Thema auftritt, werden mit der passenden Kategorie verschlagwortet – das sogenannte Kategorisieren oder Codieren. Innerhalb dieses Prozesses können die Codier-Häufigkeiten – „Wie oft oder in wie vielen Fällen bzw. Dokumenten wurde eine Kategorie vergeben?“ – zum Ausgangspunkt der statistischen Analyse gemacht werden.
Aus dem quantitativen Verfahren der „Inhaltsanalyse“ heraus wurde die „Qualitative Inhaltsanalyse“ entwickelt. Erst seit dem Aufkommen der Qualitativen Inhaltsanalyse wird die ursprüngliche „Inhaltsanalyse“ auch als „Quantitative Inhaltsanalyse“ bezeichnet, um Verwechselungen vorzubeugen. Gleichzeitig wurde jedoch auch im Diskurs der quantitativen Forschung die Inhaltsanalyse mit qualitativen Öffnungen weiterentwickelt, wodurch eine gewisse Annäherung beider Varianten stattfand.
Das könnte Dich interessieren
Unterscheiden lassen sich die Varianten inzwischen am besten daran, ob der erste Schritt der Kategorisierung der Daten automatisiert und entlang eines zuvor aufgestellten Wortkatalogs geschieht (quantitativ) oder ob die Daten gelesen, interpretiert und die Kategorien manuell zugewiesen werden (qualitativ). Durch das interpretative Kategorisieren können Qualitative Inhaltsanalysen nicht nur für die Auswertung von Texten, sondern ebenso von Bildern, Audios und Videos genutzt werden. Für die an die Kategorisierung anschließenden Analyse-Phase lassen sich sowohl in der Quantitativen Inhaltsanalyse Empfehlungen für eine teil-qualitative Auswertung wie auch in der Qualitativen Inhaltsanalyse Untervarianten einer rein statistischen Analyse finden. Aufgrund dessen sowie aufgrund der praktischen Bedürfnisse der hier dargestellten Anwendung wird im Folgen nicht mehr zwischen Quantitativer und Qualitativer Inhaltsanalyse, sondern zwischen einer quantitativen oder qualitativen Kategorisierungs- und Analyse-Phase unterschieden. Zudem wird aufgrund des Textcharakters der „praktischen Anleitung“ auf eine Differenzierung der Vorschläge und Unterverfahren verzichtet, die sich sowohl im Diskurs der Quantitativen als auch der Qualitativen Inhaltsanalyse finden.
Kategorisierungsprozess
Die Freitextantworten aus einer Online-Survey auf die offene Frage „Was sind aus Ihrer Sicht die gegenwärtig größten Weltprobleme?“ sollen kategorisiert werden.
1. Materialauswahl und Bestimmung der Analyseeinheit bestimmen
Zunächst sollte durchdacht werden, welcher Ausschnitt des Datenmaterials kategorisiert werden soll. Im Idealfall werden sämtliche Antworten auf die genannte Frage kategorisiert. Falls dies aus forschungsökonomischen Gründen nicht möglich ist, muss eine Sub-Stichprobe der erhobenen Daten ausgewählt werden. Dafür gelten die grundsätzlichen Überlegungen zu Sampling-Strategien: Die Sub-Stichprobe kann z.B. per Zufall, nach soziodemographischen Aspekten oder auch nach Inhalten gewählt werden. In diesem Beispiel könnten aufgrund einer inhaltlichen Auswahl etwa speziell die Antworten derjenigen Teilnehmenden gesichtet werden, die auf die geschlossene Frage „Hat die Welt gegenwertig kaum (1) oder sehr große (5) Probleme?“ mit 1 oder 5 antworteten, da für das Projekt gerade die Sicht der „Ränder“ von Interesse ist. Die Antworten werden pro Fall, das heißt pro Person dargestellt.
2. Festlegung: deduktive oder induktive Kategorien
Danach muss überlegt werden, ob die Kategorien deduktiv aus der Theorie oder induktiv aus den Antworten selbst abgeleitet werden sollen. Soll beispielsweise eine aus der Theorie stammende Klassifizierung der größten Weltprobleme als Raster an das Datenmaterial angelegt werden, um Übereinstimmungen zu überprüfen, werden die genannten Weltprobleme als Kategorien erzeugt und an entsprechenden Antworten vergeben – demnach eine deduktive Kategorienanwendung. Soll hingegen aus den konkreten Antworten heraus eine Klassifizierung der Weltprobleme erstellt werden, so werden die Antworten gesichtet und dazu passende Kategorien entwickelt, um Antworten zu speziellen Antworttypen zu gruppieren – somit eine induktive Kategorienentwicklung. In der Praxis kommen oft Wechselspiele vor, bei denen das Kategorisieren mit einem deduktiven ‚Start-Kategoriensystem‘ beginnt und während des Prozesses weitere, im deduktiven Raster noch nicht berücksichtigte Themen als induktive Kategorien ergänzt werden. Dadurch kann einerseits die aus der Theorie stammende Klassifizierung der Weltprobleme überprüft werden (welche wurden genannt und welche nicht?), andererseits können dabei unberücksichtigte, aber scheinbar für die Teilnehmenden relevante Weltprobleme entdeckt werden.
3. Kategorien erzeugen
Im Fall deduktiver Kategorien werden diese zunächst abgeleitet. Im oben genannten Beispiel wird die aus der Theorie stammende Klassifizierung betrachtet und aus jedem darin genannten Weltproblem eine Kategorie erzeugt. Die Kategorien werden mit Definitionen bestückt, die eine Beschreibung, ein Beispiel (eine mit der Kategorie versehene Antwort) und bei Bedarf Regeln, etwa zur Abgrenzung von anderen, aber thematisch ähnlichen Kategorien, beinhalten. Das Ergebnis ist eine (eventuell hierarchische) Liste von Kategorien, die mit entsprechenden Definitionen erweitert wurden.
Im Fall eines rein induktiven oder eines deduktiv-induktiv-gemischten Kategoriensystems wird ein Teil der Daten in einem Testdurchlauf kategorisiert, um die induktiven Kategorien zu generieren. Obwohl in der Methodenliteratur oft empfohlen wird, einen bestimmten Prozentsatz der Daten in diesen Testlauf einzubeziehen, sollte der Anteil meines Erachtens am Sättigungsgefühl statt an auf Durchschnittswerten beruhenden, prozentualen Empfehlungen festgemacht werden. Die erzeugten Kategorien werden dafür gesichtet und sortiert, wobei nah aneinander liegende Kategorien zusammengelegt werden (z.B. Bodenverschmutzung und Wasserverschmutzung zu Umweltverschmutzung) oder Kategorien andersherum nachträglich ausdifferenziert werden können. Nach Abschluss des Testlaufs steht das provisorische Kategoriensystem, das ebenfalls als (eventuell hierarchische) Liste von Kategorien dargestellt wird. Es gibt unterschiedliche Meinungen dazu, ob auch induktive Kategorien definiert werden müssen. Diese Entscheidung sollte meines Erachtens dringend projektspezifisch getroffen werden: Je klarer die Bedeutung induktiver Kategorien allein anhand ihrer Kategorienbezeichnung (ihres Codelabels) ist, desto unwahrscheinlicher, dass eine Definition notwendig wird.

Abbildung 1: Kategoriensystem. Dargestellt in MAXQDA 2020, Liste der Codes.
Abbildung 1 zeigt den Ausschnitt eines Kategoriensystems. Die Oberkategorie repräsentiert die offene Frage „Was sind aus Ihrer Sicht die größten Weltprobleme?“. Die Subkategorien stellen die konkreten Weltprobleme dar; aus der Theorie stammende (deduktive) Kategorien wurden mit einem gelb-roten und aus den Daten heraus ergänzte (induktive) Kategorien einem gelb-blauen Symbol versehen. Das gesamte Kategoriensystem dieses Projekts umfasst noch weitere, hier nicht dargestellte Ober- und Subkategorien für andere offene Fragen des Fragebogens.
4. Daten kategorisieren
4.1. Qualitativ – interpretativ
Bei dem qualitativen Prozess der Kategorisierung, der die Qualitative Inhaltsanalyse ausmacht, wird eine Antwort gelesen und mindestens einer Kategorie zugeordnet. Aufgrund der bewusst gewählten Frageformulierung im Plural („… größten Weltprobleme?“) soll und wird es zwangsläufig Antworten geben, die mehrere Weltprobleme aufzählen. Solche Antworten werden mehreren Kategorien zugeordnet. In diesem Fall muss nicht die gesamte Antwort mehrfach kategorisiert werden. Stattdessen können die einzelnen Teile der Antwort bzw. Aufzählung den entsprechenden Kategorien zugeordnet werden (vgl. Abbildung 2).

Abbildung 2: Antwort mit Kategorien-Zuordnung. Dargestellt in MAXQDA 2020, Dokument-Browser.
Wird eine (zumindest teilweise) induktive Kategorienbildung durchgeführt, kann es sein, dass trotz des Testlaufs auch in der Hauptphase des Kategorisierens, also in späteren Antworten neue Themen auftauchen. Sie sollten sich frei fühlen, auch in dieser Phase neue induktive Kategorien zu erzeugen, wenn diese für das Projekt einen Mehrwert darstellen.
Auf diese Weise wird Antwort für Antwort durchgearbeitet.
Das könnte Dich interessieren
4.2. Quantitativ – über Wortkataloge
Die Alternative zur interpretativen Erschließung der Antwort (lesen, Kategorien auswählen, zuordnen) ist die automatisierte Kategorisierung der Daten über zuvor aufgestellte Wortkataloge, wie sie in der Quantitativen Inhaltsanalyse geschieht. Dabei durchsucht eine Analyse-Software die Daten und vergibt beim Auftreten von Suchbegriffen die entsprechenden Kategorien. Abbildung 3 zeigt einige der verwendeten Kategorien (links) und die Suchbegriffe, welche die Kategorisierung mit „Klima“ auslösen (rechts).

Abbildung 3: Wortkatalog für Auto-Kategorisierung. Dargestellt in MAXQDA 2020, MAXDictio Diktionär.
Der Nachteil dieses Verfahrens ist, dass nicht vorhergesehen Formulierungen, Synonyme, Umschreibungen sowie Antworten mit Tippfehlern nicht codiert werden. Die Themen müssen manifest (explizit) in den Daten stecken; das latente (implizite) Auftreten von Themen wird hingegen nicht erkannt. Eine qualitativ-interpretative Kategorisierung der Daten ist daher vorzuziehen, wenn sie aus forschungsökonomischer Sicht realisierbar ist.
5. Quantifizierung
Am Ende des Prozesses steht die Quantifizierung der Kategorien, das heißt eine Häufigkeitsauszählung, wie oft welches Weltproblem genannt wurde, oder anders formuliert, in wie vielen Antworten eine Kategorie vergeben wurde. Hier wird dies als Häufigkeitstabelle (Abbildung 4) und Diagramm dargestellt (Abbildung 5):
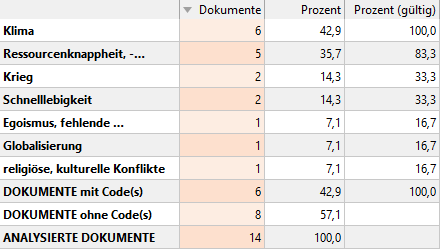
Abbildung 4: Häufigkeitstabelle. Darstellt mit MAXQDA 2020, Statistik für Subcodes.
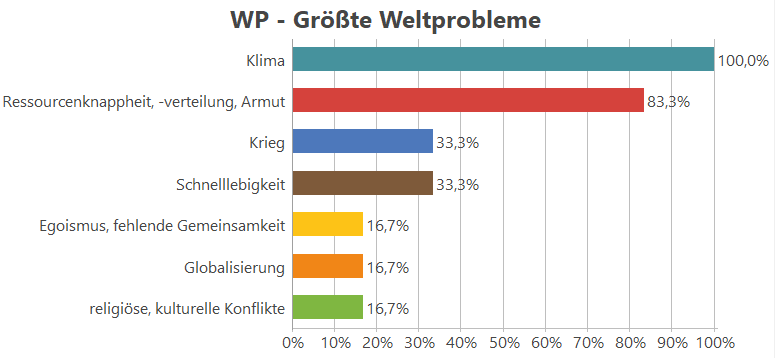
Abbildung 5: Häufigkeitsdiagramm. Dargestellt mit MAXQDA 2020, Statistik für Subcodes.
Das könnte Dich interessieren
Ausblick: Auswertung
Die Kategorisierung der Daten und deren Quantifizierung sind abgeschlossen, sodass die eigentliche Auswertung beginnen kann. Für die Analyse können quantitative wie qualitative Verfahren genutzt werden. Das simpelste Beispiel einer rein statistischen Auswertung und Ergebnisdarstellung wurde im letzten Abschnitt schon gezeigt: die einfache Häufigkeitsanalyse als Tabelle oder Diagramm. Durch die Darstellung der fallspezifischen Nennungen als Mehrfachantwortset (vgl. Abbildung 6) ist darüber hinaus ein großes Spektrum statistischer Verfahren denkbar.

Abbildung 6: Mehrfachantwortenset. Dargestellt in MAXQDA 2020, Dateneditor für Dokumentvariablen.
Aber auch der qualitativ-interpretative Blick auf die Daten kann zu interessanten Ergebnissen führen. Beispielsweise wurde das Problem der Schnelllebigkeit in der oben gezeigten Antwort dadurch ergänzt, dass daraus Krankheiten entstehen könnten. Sind solche Informationen für die Leser*innen der eigenen Arbeit von Interesse, sollten sie interpretativ zu einem kleinen Textbaustein verdichtet werden, der die rein statistische Ergebnisdarstellung ergänzt.
Das könnte Dich interessieren
Beispiel 1 „Qualitative Inhaltsanalyse in Auftragsforschung“ zeigt eine teils quantitativ-statistische, teils qualitativ-interpretative Ergebnisdarstellung.
Zusammenfassung
- Qualitative Daten – wie Freitextantworten auf offene Fragen – können in quantitativen Projekten durch die Quantitative bzw. Qualitative Inhaltsanalyse bzw. Mischformen kategorisiert, quantifiziert und damit in Mehrfachantwortensets überführt werden.
- Dabei werden die Antworten nach deduktiven und/oder induktiven Gesichtspunkten gruppiert.
- Die statistische Analyse auf Basis der Häufigkeiten kann um eine interpretative Analyse der Antworten ergänzt werden, etwa um Begründungen oder konkrete Kritikpunkte und Verbesserungsvorschläge darzustellen.
- Ein Manual zur computergestützten Umsetzung erscheint November 2020 auf diesem Blog.
Literatur zur Einführung
Mayring, Philipp; Frenzl, Thomas (2019): Qualitative Inhaltsanalyse. In: Nina Baur, Jörg Blasius (Hrsg.). Handbuch Methoden der empirischen Sozialforschung. S. 633-648. Wiesbaden: Springer VS.
Züll, Cornelia; Menold, Natalja (2019): Offene Fragen. In: Nina Baur, Jörg Blasius (Hrsg.). Handbuch Methoden der empirischen Sozialforschung. S. 855-862. Wiesbaden: Springer VS.
Das könnte Dich interessieren
Literatur zur Vertiefung
Früh, Werner (2017): Inhaltsanalyse. 9. Auflage. Konstanz/München: UVK Verlagsgesellschaft.
Kuckartz, Udo (2018): Qualitative Inhaltsanalyse. Methoden, Praxis, Computerunterstützung. 4. Auflage. Weinheim/Basel: Beltz Juventa.
Mayring, Philipp (2015): Qualitative Inhaltsanalyse: Grundlagen und Techniken. 12. Auflage. Weinheim/Basel: Beltz.
Rössler, Patrick (2017): Inhaltsanalyse. 3. Auflage. Konstanz/München: UVK Verlagsgesellschaft.
Sommer, Katharina u.a. (Hrsg.) (2014): Automatisierung in der Inhaltsanalyse. Reihe: Methoden und Forschungslogik der Kommunikationswissenschaft. Köln: Herbert von Halem Verlag.

Ich bin Diplom-Sozialwissenschaftler mit Zusatzqualifikation für Gender Studies, habe 2010-2015 in der Methodenlehre am Institut für Soziologie der Universität Hannover gearbeitet und mich 2015 hauptberuflich selbstständig gemacht. Unter dem Namen Methoden Coaching Morgenstern biete ich seither Dienstleistungen rund um qualitative Forschung und Mixed Methods an. Du kannst mich für individuelle oder gruppenspezifische Beratung, für Lehrveranstaltungen und für Auftragsforschung buchen. Außerdem bin ich Professional Trainer der QDA-Software (Qualitative Data Analysis) MAXQDA. Auf meinem YouTube-Kanal behandle ich methodische und praktische Fragen der qualitativen Forschung: http://youtube.methoden-coaching.de




Hallo, ich habe eine Frage bezüglich meiner Auswertung. Ich möchte für meine Bachelorarbeit herausfinden in wie fern verschiedene Elemente einer Werbeanzeige etwas mit der Erinnerung zu tun haben. In der Tabelle findet man eine Spalte mit Erinnerung. 1 bedeutet Anzeige erinnert, 2 bedeutet Anzeige nicht erinnert. Dann gibt es die Spalte Farbe. Hier wird zwischen 1 farbig, 2 schwarz-weiß, 0 nicht an das Element Farbe erinnert unterschieden. Dann die Spalte Position 1 links, 2 rechts, 3 mittig, 0 bedeutet nicht an das Element Position erinnert. Dann die Spalte Bild mit 1 an ein Bildelement erinnert, 0 an kein Bild erinnert. Bei Spalte Text bedeutet 1 Slogan, 2 Text, 3 Logo, 0 keine Erinnerung an ein Textelement. Zum Schluss gibt es die Spalte Größe mit 1 klein, 2 mittel, 3 groß und 0 keine Erinnerung an die Größe. Nun habe ich eine ähnliche Häufigkeitstabelle wie oben aber auch ein Mehrfachantwortenset. Um verschiedene Hypothesen zu testen benötige ich ja statistische Tests um den p-Wert zu berechnen oder fällt das hier bei meinem Beispiel raus? Kann ich auch durch zum Beispiel eine Häufigkeitstabelle meine Hypothesen bestätigen?
Hallo Robin,
es kommt ganz auf deine Hypothesen an. Wenn du als Hypothese den Zusammenhang zwischen zwei dieser Variablen untersuchen willst, musst du eine Kreuztabelle aus den beiden erstellen und kannst die dann beispielsweise mit dem Chi-Quadrat-Test auf Signifikanz prüfen.
Es kann aber auch sein, dass deine Hypothese nur eine Variable betrifft und du z.B. untersuchen willst, ob der Anteil der Angabe „farbig“ über 50 % liegt. Dann bleibst du bei der Häufigkeitstabelle und rechnest zusätzlich einen Binomialtest.
LG Daniela