Abbildungen machen Deinen Ergebnisteil anschaulicher und leichter verständlich und lockern lange Textabschnitte auf. Abbildungen sind ein deskriptives, also beschreibendes Mittel. Das heißt auch, dass erstmal grundsätzlich nichts „verboten“ ist. Aber es gibt durchaus sinnvolle oder weniger sinnvolle Arten der Darstellung. Außerdem kann man durch Abbildungen auch gekonnt den Leser in die Irre führen und somit gewollt oder ungewollt täuschen.
Damit Dir das nicht passiert und Du die sinnvolle Abbildungsart auswählst, gebe ich Dir hier meine 5 No-Gos, die Du vermeiden solltest.
1. Kreisdiagramm für kategoriale Daten

Oft werden Kreisdiagramme oder Tortendiagramme verwendet, um die Häufigkeiten der Kategorien von kategorialen Variablen darzustellen. Allerdings sind Kreisdiagramme vor allem bei mehreren Kategorien und auch bei teils kleinen Kategorien schwierig zu lesen. Außerdem werden Kreisdiagramme gern dreidimensional verwendet und schräg gelegt, was das Lesen noch schwieriger macht. Durch das „Drehen“ des Kreises kann außerdem der Eindruck auf den Leser verändert werden.
Deshalb empfehle ich keine Kreisdiagramme einzusetzen, sondern stattdessen einfach ein Balkendiagramm zu verwenden. Das ist einfacher zu lesen, man kann damit den Leser nicht täuschen und es kann sogar mit Gruppierung (farbige Balken) erstellt werden.
2. Balken für den Mittelwert
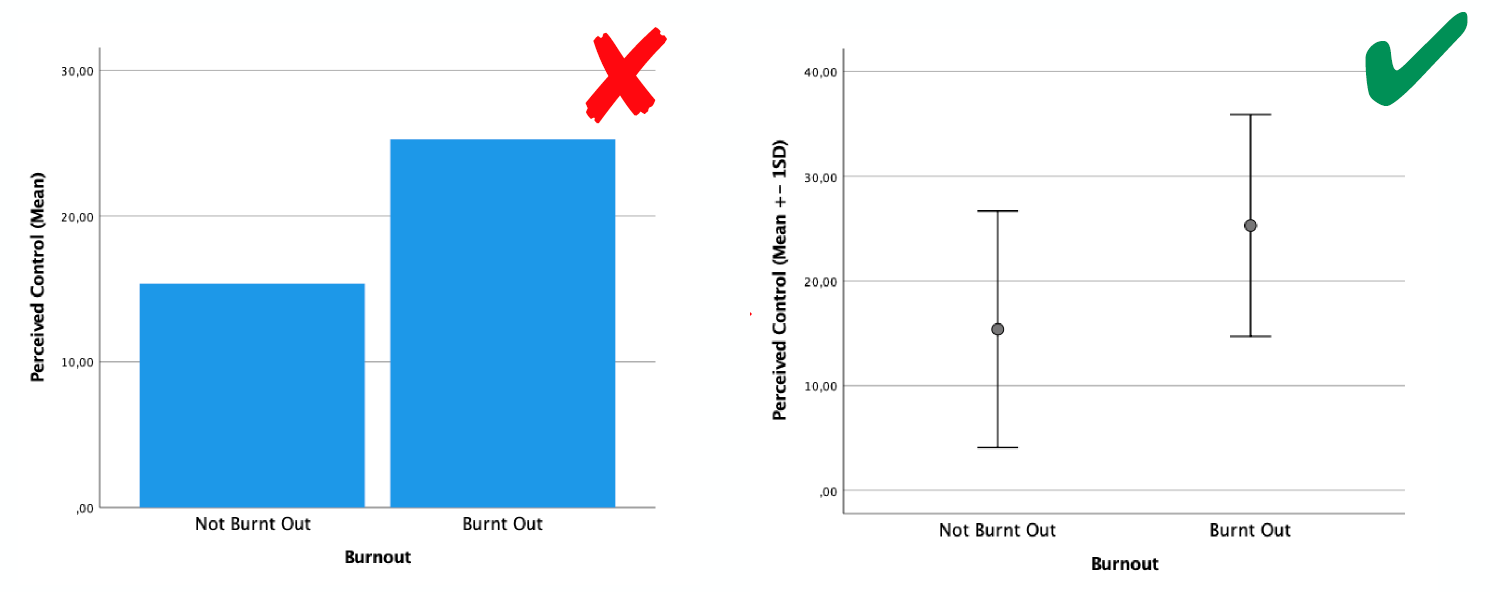
Häufig sieht man in Publikationen, dass für die Darstellung eines Mittelwerts ein Balkendiagramm verwendet wird. Die Höhe des Balkens stellt dann den Mittelwert dar und es werden teils noch Fehlerlinien mit angegeben. Die Verwendung eines Balkens ist hier meine Ansicht nach nicht sinnvoll. Der Balken passt besser zur Darstellung von Häufigkeiten und nicht für ein Lagemaß, was der Mittelwert ja ist. Auffällig wird das dann, wenn man einen negativen Mittelwert darstellen will. Da geht der Balken dann nach unten (?!).
Besser ist es, für die Darstellung von Mittelwerten einfach einen Punkt oder Kreis zu verwenden, von dem dann noch Fehlerlinien nach oben und unten weggehen, die die Streuung oder ein Konfidenzintervall anzeigen.
Du willst mehr Durchblick im Statistik-Dschungel?
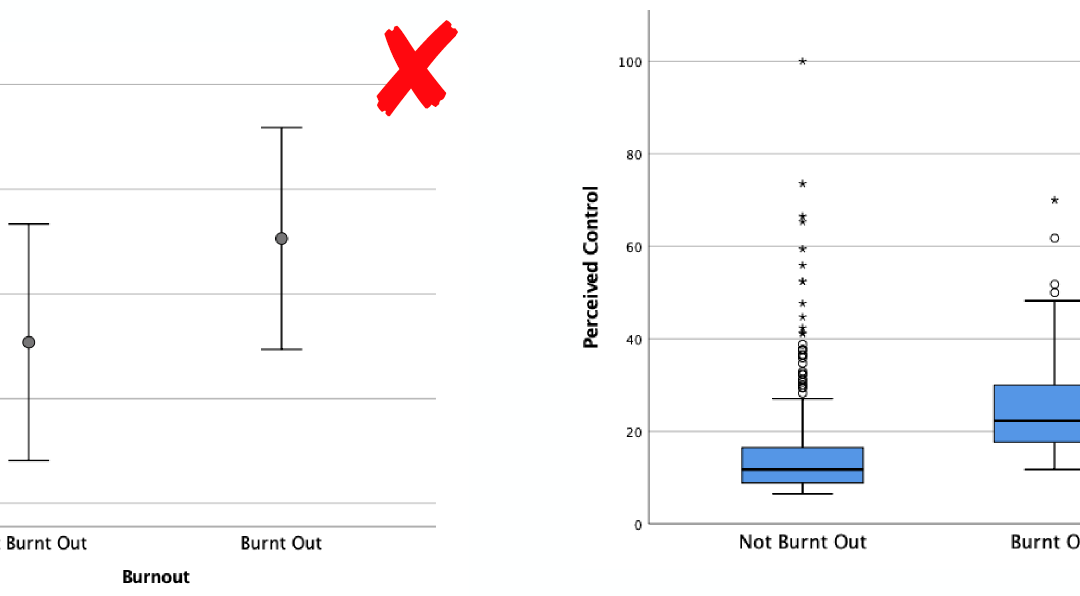
3. Mittelwertdiagramm bei schiefen Daten oder Ausreißern
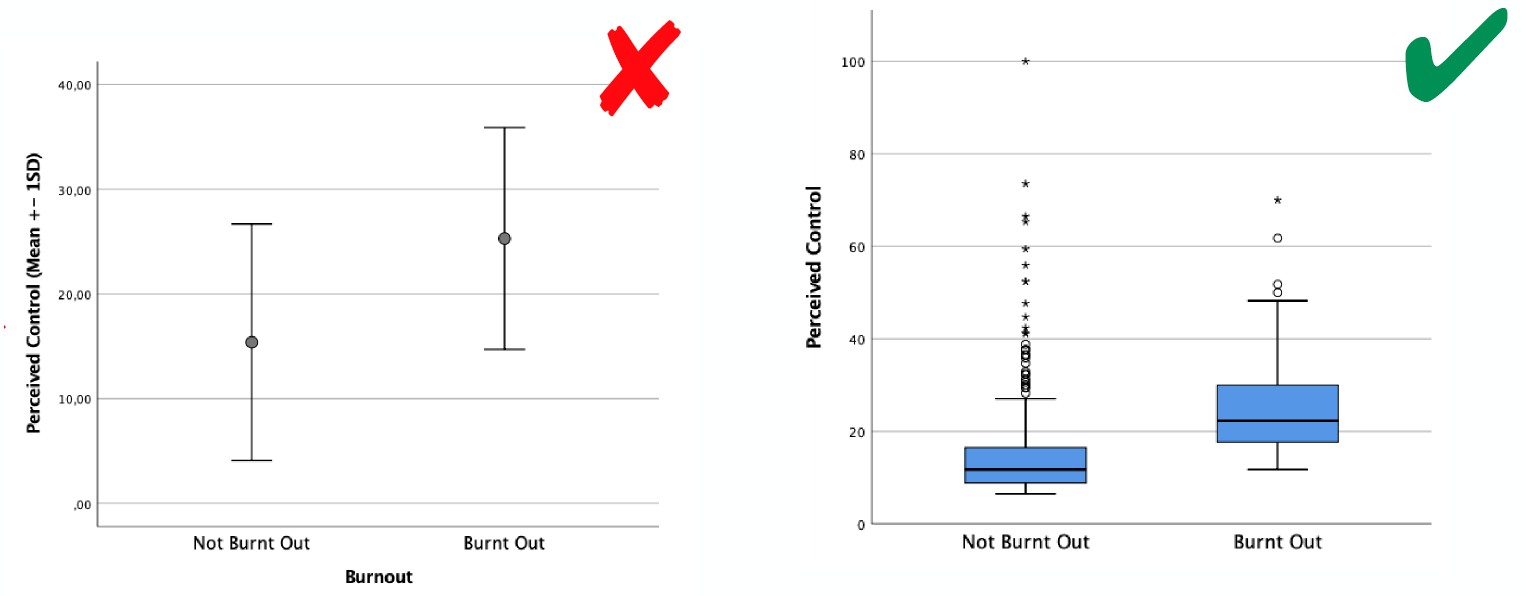
Wenn Du schiefe Daten hast oder Ausreißer vorkommen, dann solltest Du nicht den Mittelwert als Darstellung verwenden. Denn der Mittelwert (und die meist dazu verwendete Standardabweichung) können die Schiefe der Daten nicht abbilden und werden stark von Ausreißern beeinflusst. Die Lage und auch die Streuung wird deshalb von diesen Maßen nicht richtig dargestellt. In der Abbildung siehst Du die Schiefe dann nicht mehr und es ist auch nicht ersichtlich, dass es mal Ausereißer gab. Du hast Dir damit dann die Daten eventuell „schön“ gerechnet und das ist nicht in Ordung.
Besser ist es, wenn Du in diesen Fällen mit dem Boxplot arbeitest. Dort wird die Lage mittels Median und die Streuung mittels Quartilen (Box) dargestellt. Außerdem siehst Du anhand der Linien, wo die kleinste und wo die größte Beobachtung lag und Ausreißer werden extra markiert. Damit siehst Du auf einen Blick also neben Lage und Streuung auch die Schiefe und mögliche Ausreißer Deiner Daten. Somit ist der Boxplot sehr transparent. Es wird nichts „weg-gerechnet“ und der Leser kann sich selbst ein Bild von den Daten und Ergebnissen machen.
4. Verwendung des Standardfehlers (SE) als Fehlerbalken
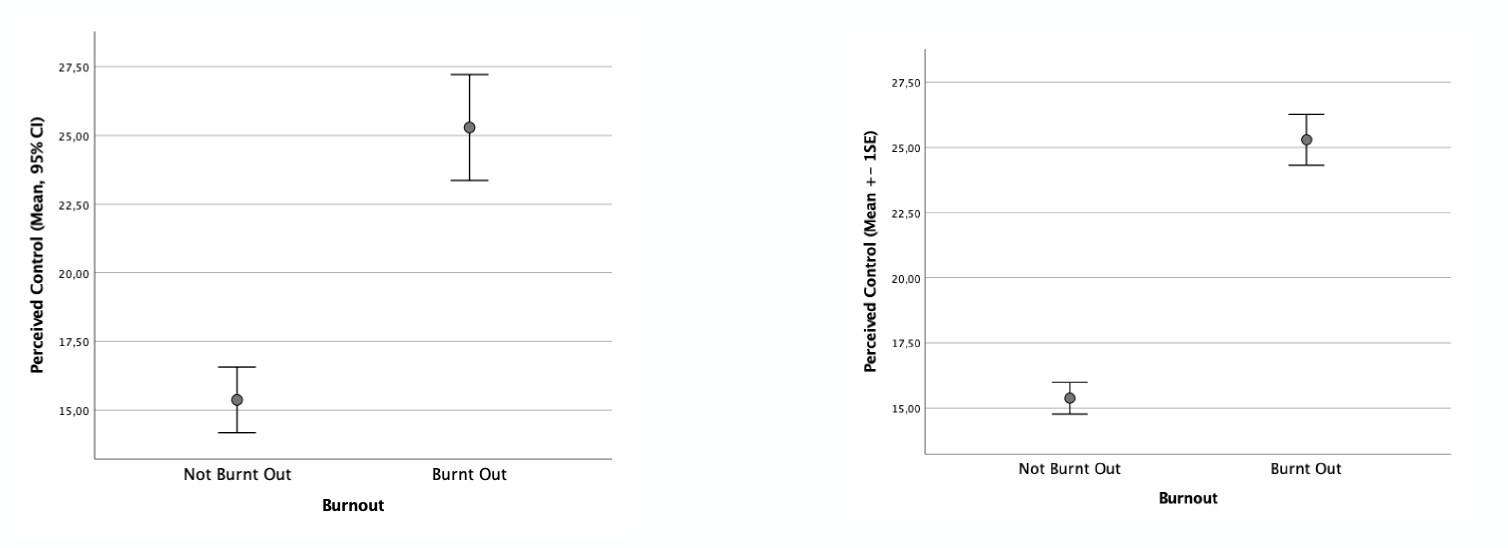
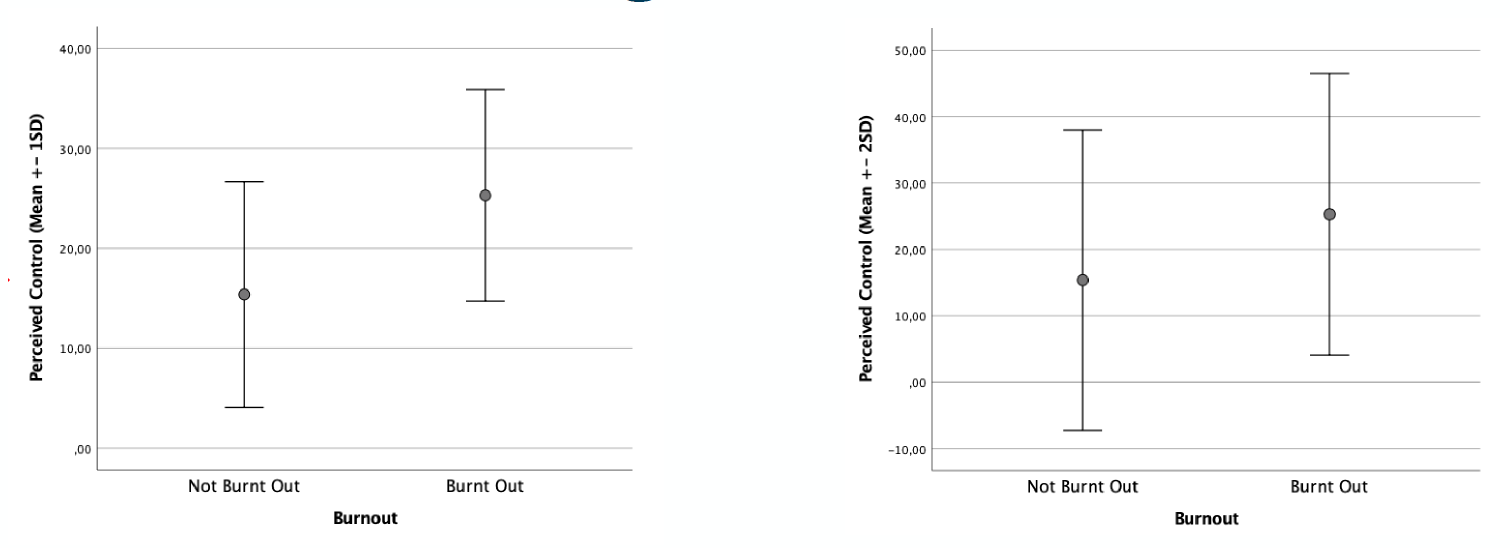
Wenn Du annähernd normalverteilte Daten hast, dann macht es Sinn, die Daten mittels Mittelwertdiagramm darzustellen. Zusäztlich zum Mittelwert (als Kreis) solltest Du unbedingt auch ein Streumaß mit angeben, das Du als Fehlerlinien nach oben und unten anträgst.
Es gibt verschiedene Möglichkeiten für die Berechnung dieser Fehlerlinien und keine davon ist wirklich falsch. Sie fallen aber teils sehr unterschiedlich aus. Und so ist es sehr wichtig, dass Du genau mit angibst, um welche Art der Fehlerlinien es sich handelt. Ansonsten kann der Leser die Abbildung nicht richtig interpretieren.
Du kannst die Standardabweichung (SD) verwenden, da sie die Streuung der Daten um den Mittelwert beschreibt. Sie ist ein reines deskriptives Maß das unabhängig von der Fallzahl ist und damit für rein deskriptive Ziele perfekt. Oft wird auch 2*SD verwendet (zweimal die Standardabweichung). das hat den Grund, dass man bei normalverteilten Daten weiß, dass in dem Bereich um plus und minus 2-SD ca. 95 % der Beobachtungen liegen. Wenn Du 2*SD als Fehlerlinien nimmst zeigst Du also einen Bereich, in dem ein Großteil der Fälle liegt. Beides (1*SD und 2*SD) ist sinnvoll für die Visualisierung von Streuung. Wichtig ist, dass Du in der Achsenbeschriftung oder in der Abbildungsbeschreibung angibst, was Du verwendest. Ansonsten kann man die Abbildung nicht sinnvoll lesen.
Manchmal wird auch der Standardfehler (SE) verwendet. Der Standardfehler hängt aber nicht nur von der Streuung (SD) sondern auch von der Fallzahl ab. Bei größerer Fallzahl wird der Standardfehler automatisch kleiner. Das hat zur Folge, dass der Standardfehler oft „schön klein“ aussieht. Abbildungen, die einen Unterschied zeigen sollen, wirken mit dem Standardfehler als Fehlerlinie oft extremer als es in Wahrheit der Fall ist. Deshalb kann man damit leicht einen deutlichen Unterschied vortäuschen. Aus meiner Sicht eignet sich der Standardfehler deshalb NICHT zur Visualisierung.
Eine besser Möglichkeit Mittelwertsunterschiede zu visualisieren ist die Verwendung von Konfidenzintervallen. Das Konfidenzintervall wird zwar aus dem Standardfehler berechnet (beim 95 %-Konfidenzintervall ist eine Fehlerlinie ca. 2*SE) und hängt damit auch von der Fallzahl ab. Da es aber zudem ähnlich wie ein Signifikanztest verwendet werden kann, ist die Interpretation trotzdem sinnvoll. Indem Du schaust, ob sich zwei Konfidenzintervalle überlappen oder nicht, kannst Du (annähernd) entscheiden, ob es einen signifikanten Unterschied gibt oder nicht.
Wenn Du also auch etwas über Signifikanz mit Deiner Abbildung aussagen willst, dann nimm gern das Konfidenzintervall. Wenn es Dir um eine reine deskriptive Darstellung geht, nimm gern die Standardabweichung (1*SD oder 2*SD). Den Standardfehler solltest Du lieber vermeiden.
5. Kurve im Streudiagramm
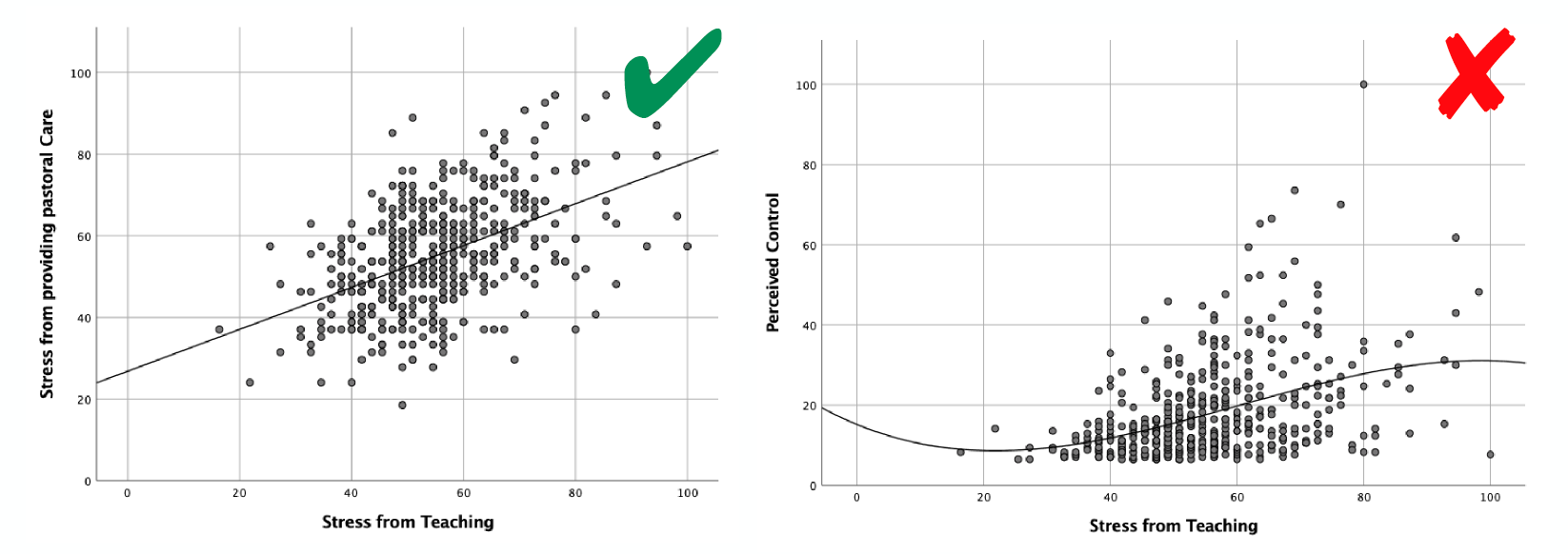
Den Zusammenhang zwischen zwei metrischen Variablen kannst Du gut in einem Punkt- oder Streudiagramm darstellen. Gerne legst Du Dir hier auch eine Trendgerade hinein, die den visuellen Eindruck des Zusammenhangs noch unterstreicht. Bitte versuche aber nicht, eine Kurve anzupassen. Eine Kurve solltest Du nur verwenden, wenn Du ganz klar eine Kurve erkennst und am besten die Funkion auch inhaltlich Sinn macht oder Du die nichtlineare Funktion auch in einer weiteren Analyse (z.B. Nichtlineare Regression) bestätigt hast.
Du willst mehr Durchblick im Statistik-Dschungel?

Ich bin Statistik-Expertin aus Leidenschaft und bringe Dir auf leicht verständliche Weise und anwendungsorientiert die statistische Datenanalyse bei. Mit meinen praxisrelevanten Inhalten und hilfreichen Tipps wirst Du statistisch kompetenter und bringst Dein Projekt einen großen Schritt voran.



