
In diesem Beitrag möchte ich dir zeigen, wie die Koeffizienten der linearen Regression interpretiert werden.
Mittels linearer Regression wird der lineare Zusammenhang zwischen einer Zielvariablen Y, im medizinischen Bereich z.B. der Blutdruck und einer oder mehreren Einflussvariablen X (Gewicht, Alter, Geschlecht…) untersucht. Die Zielvariable Y muss dabei stetig sein, die Einflussvariablen können stetig (Alter), binär (Geschlecht) oder kategorial (Sozialer Hintergrund) sein. Meist wird für die bivariaten (also paarweisen) Zusammenhänge zunächst ein Streudiagramm (Punktwolke) erstellt, wodurch sichtbar wird, ob es sich um einen linearen oder einen nichtlinearen Zusammenhang handelt. Bei einem linearen Zusammenhang kann man quasi eine Grade durch die Punktwolke ziehen.
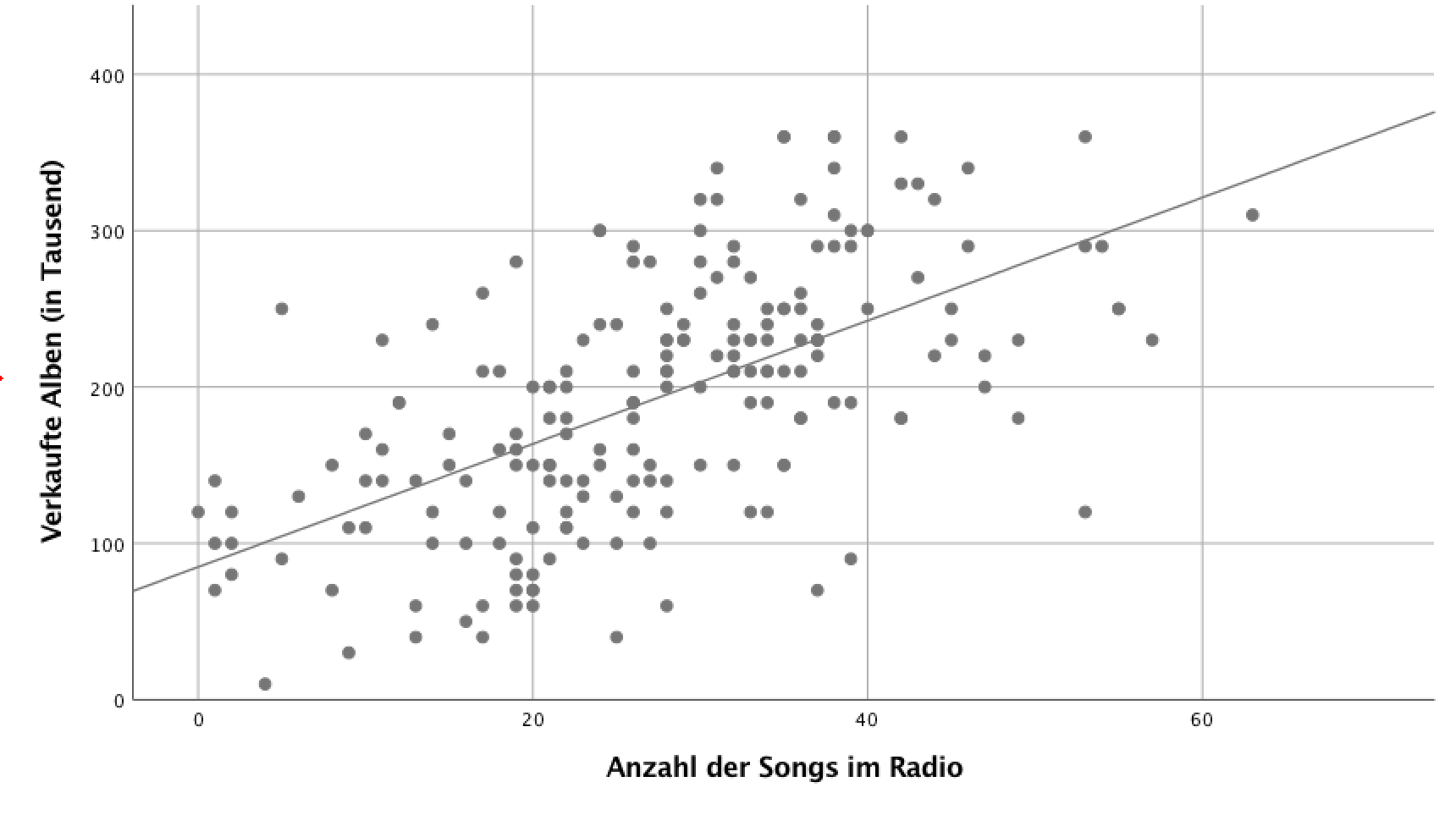
Einfache lineare Regression
Das lineare Regressionsmodell beschreibt die Zielvariable durch eine Gerade Y = a + b × X, mit a = Achsenabschnitt und b = Steigung der Geraden. Zunächst werden aus den Werten der Zielvariablen Y und der Einflussvariablen X die Parameter a und b der Regressionsgerade mit Hilfe statistischer Methoden geschätzt. Die Gerade ermöglicht, Werte der Zielvariablen Y durch Werte der Einflussvariablen X vorherzusagen.
Wenn du eine einfache lineare Regression rechnest, hast du eine metrische abhängige Variable und einen metrischen Faktor (= unabhängige Variable). Im Ergebnis der Regression bekommst du dann den Regressionskoeffizienten (b) dieses Faktors. An ihm lässt sich der Beitrag der Einflussvariablen X für die Erklärung der Zielgröße Y ablesen. Bei einer stetigen Einflussgröße (zum Beispiel Körpergröße in cm) beschreibt der Regressionskoeffizient die Veränderung der Zielvariablen (Körpergewicht in kg) pro Maßeinheit der Einflussvariablen (Körpergröße in cm). Du kannst den Regressionskoeffizienten also auch zur direkten Interpretation verwenden: Wenn der Faktor sich um eine Einheit ändert, dann ändert sich die abhängige Variable um b Einheiten.
Zudem erhält man einen p-Wert. An der Höhe und Richtung (positiv oder negativ) siehst du den Einfluss des Faktors auf die abhängige Variable: stark, schwach, positiv, negativ. Der p-Wert sagt dir zusätzlich, ob dieser Regressionskoeffizient sich signifikant von 0 unterscheidet, also ob der Einfluss signifikant ist.
Du willst mehr Durchblick im Statistik-Dschungel?
Multiple Regression
In diesem Fall bekommst du für jeden Faktor einen Regressionskoeffizienten und einen p-Wert. Der p-Wert gibt dir wieder an, ob der Einfluss dieses Faktors auf die abhängige Variable signifikant ist. Den Regressionskoeffizienten kannst du wieder für die Linearkombination der Modellformel verwenden, bzw. ihn dir als Steigung in der Regressionsgeraden vorstellen. Ebenso kann er zur Interpretation des Einflusses verwendet werden. In diesem Fall beschreibt der Regressionskoeffizient von Faktor A nun die Änderung der abhängigen Variable, wenn sich Faktor A um eine Einheit ändert und gleichzeitig die anderen Faktoren / der andere Faktor im Modell konstant bleibt. Damit hast du also den Einfluss des Faktors A kontrolliert für den/die anderen Faktor(en).
Diese Interpretation der Regressionskoeffizienten als Änderung pro Einheit hängt von der Skalierung des Faktors ab. Deshalb ist es nicht sinnvoll, die unterschiedlichen Faktoren miteinander zu vergleichen, wenn sie unterschiedlich skaliert sind. Deshalb solltest du zum Vergleich der Faktoren nicht die „normalen“ Regressionskoeffizienten, sondern die standardisierten Regressionskoeffizienten verwenden. Diese sind anhand der Skala des Faktors standardisiert und deshalb untereinander vergleichbar. So kannst du dann z.B. sagen, welcher Faktor den größten Effekt hat.
Beispiel: „Atemfunktion“
Außer der Beschreibung des Zusammenhangs ist auch eine individuelle Prognose eines Patienten mit Hilfe des multiplen Regressionsmodells möglich. Es können beispielsweise Sollwerte für die Atemfunktion unter Berücksichtigung von Alter, Body-Mass-In-dex (BMI) und Geschlecht erstellt werden. Durch den Vergleich des ermittelten Wertes für einen Patienten mit dem Sollwert kann man Schlussfolgerungen hinsichtlich seines Gesundheitszustandes ziehen.
Bei der multiplen Regressionsanalyse ist das Ziel herauszufinden, welche der Faktoren tatsächlich einen Einfluss auf die Zielvariable haben. Es muss die Variable gefunden werden, die die Zielvariable am ehesten erklärt.
Ich hoffe ich konnte euch mit dem Beitrag weiter helfen und stehe wie immer gerne bei weiteren Fragen zur Verfügung.
Die 10 häufigsten Fehler bei Abschlussarbeiten mit SPSS und wie du sie vermeidest.
Hol dir jetzt die Liste für 0,- Euro und komm mit deiner Datenanalyse fehlerfrei und schnell voran!
Ich bin Studentin der Betriebswirtschaftslehre an der FHWS und habe zuvor ein Studium der Empirischen Bildungsforschung und der Sonderpädagogik an der Julius-Maximilians-Universität Würzburg absolviert. Statistik begeistert mich! Besonders die freie Statistiksoftware R hat es mir angetan. Deshalb schreibe ich hier ab und zu im Blog von Statistik & Beratung kleine Beiträge zu Statistikthemen und deren Umsetzung in R. Ich freue mich auf euer Feedback und eure Kommentare!




Hallo Daniela,
ich schreibe gerade meine Bachelorarbeit und habe Regressionen nach der Einschlussmethode gerechnet.
Woran kann es liegen, wenn
1. Das Modell signifikant wird, aber die einzelnen Prädiktoren nicht.
2. Das Modell nicht signifikant wird, aber 1 Prädiktor signifikant ist.
Und was heißt das nun?
Ich hoffe du kannst mir hier weiterhelfen.
Tausend Dank schon einmal.
Viele Grüße, Lene
Hallo Lene,
vermutlich sind die Signifikanzen dann knapp, oder?
Schöne Grüße
Daniela
Hallo Daniela,
ich habe eine Frage zur Interpretation der Koeffizienten, wenn die abhängige Variable diskret ist.
Die Variable steht für den Notendurchschnitt und kann die Ausprägungen 1,2 1,7 2,2 2,7 3,2 oder 3,7 annehmen. Der Abstand ist somit immer 0,5 (Dabei handelt es sich um die Mittelpunkte von Intervallen). Ich hoffe, dass man in diesem Fall überhaupt eine lineare Regression anwenden kann.
Zum Beispiel nimmt der Koeffizient für das Alter den Wert -0,06 an.
Muss ich für die Interpretation nun den Abstand zwischen den Noten berücksichtigen und 0,06 * 0,5 rechnen? Sodass ich zu dem Ergebnis komme, dass wenn die Person ein Jahr älter ist, die Note um 0,03 sinkt ? (die Person also um 0,03 Notenpunkte besser wird)
Liebe Grüße und vielen Dank für deine Antwort,
Tina
Hallo Tina,
damit hier trotzdem die lineare Regression verwendet werden kann, müssen die Voraussetzungen dafür passen, siehe zum Beispiel meine Checkliste hier: https://statistik-und-beratung.de/2016/02/checkliste-multiple-lineare-regression/
Interpretiert werden die Koeffizienten, als wäre die abhängige Variable metrisch, also -0,06 bedeutet, dass wenn die Person ein Jahr älter wird, die Note um 0,06 sinkt, auch, wenn dieser Wert dann gar nicht in den Daten angenommen werden kann.
Weitere Fragen könnt Ihr gern in meiner Facebook-Gruppe Statistikfragen https://www.facebook.com/groups/785900308158525/ diskutieren.
Schöne Grüße
Daniela
Sehr geehrte Frau Keller,
ich finde gerade keinen richtige Ort für meine Frage, freue mich dennoch wenn Sie mir weiterhelfen können.
Ich möchte eine logistische Regression mit SPSS durchführen und stecke gerade bei der Überlegung fest, welche Kategorien (erste oder letzte) meiner ordinalen Variablen (Kovariaten) ich als Referenzkategorie auswählen soll?
Ich spreche von dem Dialogfeld bzw. der Prozedur: Logistische Regression: Kategoriale Variablen definieren: Kontrast ändern: Kontrast: Indikator u.s.w.
Ich habe gelesen, dass man eine interessante und ausreichend besetzte Kategorie nehmen soll. Meine letzten und ersten Kategorien sind schon am interessantesten, aber woher weiß ich ob sie ausreichend besetzt sind?
Vielen Dank und danke auch für diese tolle und hilfreiche Webseite.
Beste Grüße S. Knapp
Hallo Frau Knapp,
nehmen Sie die, die inhaltlich am besten passt. Zu dieser Kategorie werden dann alle anderen verglichen. Ausreichend besetzt heißt, dass sie nicht „kaum“ vorkommen soll, also nicht nur 3-mal, wenn Sie insgesamt 100 Beobachtungen haben…
Schöne Grüße
Daniela
Hallo! Ich finde diese Erläuterungen sehr hilfreich. Jedoch bleiben bei meinem Projekt einige Fragen offen. Ich möchte eine einfache lineare Regression durchführen. Mit stetigen numerischen Messwerte von verschiedenen Personen zu Woche 0, 2, 4 und 12. der Test auf normalverteilung sagt dass die Werte an den jeweils einzelnen Zeitpunkten nicht normal verteilt sind. Kann ich dann ein Modell der linearen Regression verwenden um einen evtl vorhandenen positiven oder negativen Trend über die Zeit zu erkennen und zu prüfen ob dieser signifikant ist ?
Hallo Isabelle,
das hört sich eher nach einer Varianzanalyse mit Messwiederholung bzw. Friedman-Test an.
Schöne Grüße
Daniela
Hallo Isabelle,
deine Fragestellung scheint der eines linearen gemischten Modells zu entsprechen. Dieser Modelltyp erlaubt es dir einen Zeittrend zu berücksichtigen, sowie andere Kovariablen. Zudem ist es relevant zu berücksichtigen, dass verschiedene Messwerte von der selben Person stammen. Es ist irrelevant, wie die Messwerte je Zeitpunkt verteilt sind!
Viele Grüße,
David
Sehr geehrte Frau Keller,
ich habe den Fall, dass zwei Prädiktoren bei der einfachen linearen Regression das Kriterium signfikant vorhersagen. Gebe ich sie jedoch gemeinsam in ein multiples Regressionsmodell ein, sind beide nicht mehr signfikant. Welche Gründe könnte es hierfür geben?
Mit freundlichen Grüßen
Daniel
Hallo Daniel,
wie genau sind die Ergebnisse? Sind die p-Werte knapp? Wie sind die Voraussetzungen erfüllt (Multikollinearität usw.)? Wie groß ist der Datensatz? Wie stark korrelieren die beiden miteinander? Es kann unterschiedliche Gründe für dieses Phänomen geben, da bruache ich ein paar mehr Infos, um das einzuschätzen.
Schöne Grüße
Daniela
Hallo Daniela, auf der Suche nach Hilfe für eine Interpretation meienr Ergebnisse bin ich auf deinen Blog hier gestoßen und fand deine Art und Weise sehr schön, wie du Denkanstöße geben kannst!
ich habe ein ähnliches Problem wie oben beschrieben: Ichh rechne eine Regression mit einer UV metrisch, einer Dummy Variballen und einem Interaktionseffekt aus diesen beiden. Als Ergebnis kommt heraus, dass die UV signifikant ist (ß=-.185, p=.000). bei Der dummy Variable erhalte ich das Ergebnis ß=-.065, p=.238. Die Interaktion erzielt ß=-.016, p=.789. N=1388. Multikollinearität soll ich nicht überprüfen, habe sie mir dennoch angeschaut: Die Toleranzwerte zeigen an bei UV:.628, Dummy:.226 und Interaktion:.186. Das würde ja auf ein Kollinearitätsproblem hindeuten? Ich komme momentan nicht weiter und wäre über schnelle Hilfe und Antworten wirklich sehr dankbar!
Liebe grüße, Melanie
Hallo Melanie,
die Toleranzwerte sind noch im annehmbaren Bereich. Das ist also noch in Ordnung. Deine Interaktion ist nicht signifkant,also hast Du keine Interaktion (Moderation). Nur die metrische UV hat einen signifikanten negativen Effekt.
Schöne Grüße
Daniela
Hallo Daniela,
ich habe eine Frage zu Interpretation der multiplen Regression. Wenn ich z.B den Einfluss soziodemographischer Variablen auf eine abhängige Variable berechne und ich möchte mir die Ergebnisse dann differenziert ansehen. z.B. Arbeitsstatus – es gibt einen signifikanten Zusammenhang – wie kann ich aus meinen Ergebnissen herauslesen ob etwa Studenten, Angestellte usw höhere/niedrigere Werte aufwiesen..
Vielen lieben Dank,
Jana
Hallo Jana,
dazu betrachtest du am besten die deskriptiven Werte, also Mittelwerte/SD usw für die einzelnen Gruppen.
schöne Grüße
Daniela
Liebe Frau Keller,
an erster Stelle, möchte ich mich für Ihr hilfreiches Blog herzlich bedanken.
Desweiteren bitte ich Sie um Hilfe bezüglich einer statistischen Frage, die ich im Rahmen meiner Abschlussarbeit untersuche. Mich interressiert der Einfluss zweier unabhängigen Variablen auf einer AV. Dabei ist die erste UV mit insg. 13 Items operationalisiert, die ihrerseits theoretisch 5 Unterfaktoren bilden (leider hat die Faktorenanalyse das Vorhandensein lediglich eines einzelnen Faktors gezeigt).
Nun möchte ich eine multiple Regression mit der AV und den 13 Items der UV1 berechnen, um zu schauen, welche Items / Unterktegorien die AV am besten vorhersagen. Ist solch eine Methode statistisch überhaubt zulässig bzw. sinnvoll? Alles, das ich bisher im Zusammenhang mit Multipler Regression finden konnte, behandelt den Einfluss mehrerer UVn auf die AV und nicht mehrerer UV-Ausprägungen auf die AV.
Ich bedanke mich im Voraus für Ihre Mühe und verbleibe mit freundlichen Grüßen,
Ramona
Hallo Ramona,
du hast vor, die Items alle einzeln als UVs zu verwenden. Das geht theoretisch schon, kann aber Probleme mit Multikollinearität geben, da die Items wohl stark miteinander korrelieren?
Schöne Grüße
Daniela
Hallo Daniela,
im Rahmen meiner Doktorarbeit habe ich eine binäre logistische Regression aufgestellt, mit mehreren metrischen und auch dichotomen erklärenden Variablen.
Ich möchte nun bzgl. der metrischen erklärenden Variablen eine Odds Ratio erhalten, die einer Erniedrigung der metrischen Variable um eine Einheit entspricht (sonst wird ja immer gemäß einer Erhöhung um eine Einheit interpretiert). Dazu habe ich die metrische Variable mit -1 multipliziert und in eine neue Variable berechnet – scheinbar erhalte ich dann die gewünschte Odds Ratio.
Meine Fragen: Geht das so oder mache ich einen Denkfehler?
Zweitens: Wenn ich nun nicht die Erniedrigung um eine Einheit, sondern um mehrere Einheiten betrachten möchte, wie kann ich SPSS das sagen? Ich kann zwar manuell über e^(Regressionskoeffizient*Einheitenfaktor) die entsprechende Odds Ratio berechnen, hätte aber auch gern das entsprechende 95%-Konfidenzintervall dazu…da wird es dann langsam zu hoch für mich 🙁
Viele Grüße und vielen Dank,
Moritz
Hallo Moritz,
ja, so geht das (die Multiplikation mit -1).
Genauso könntest du auch für deine zweite Frage vorgehen, also aus der bisherigen Variablen eine neue Berechnen, die einen anderen Einheitenfaktor hat. Also die Variable mit dem gewünschten Faktor multiplizieren oder teilen und dann das Modell mit der Variablen nochmal rechnen.
Schöne Grüße
Daniela
Hallo Daniela,
ich habe geplant für meine Hypothesentestung eine multiple regression zu berechnen. Allerdings scheinen die Voraussetzungen für die Regressionsanalsyse nicht erfüllt zu sein. Was ist dann hier die Alternative zu diesem Verfahren.
Besten Dank und liebe Grüße!
Hallo Jana,
es gibt – zumindest in SPSS – die Möglichkeit, die Regression mit Bootstrapping zu rechnen. Dann sind die Ergebnisse trotz bestimmter Verletzungen der Voraussetzungen verlässlich.
Schöne Grüße
Daniela
Liebes Statistik&Beratung-Team,
ich habe folgende Frage:
ln(jahresumsatz_euro) = ß0 + ß1mitarbeiter + ß2mitarbeiter^2 + ß3age +ß4age^2 + u
Unter welchen Umständen kann ich bei dieser Funktion die Konstante ß0 weglassen? Und welche Vorteile ergäben sich daraus?
Über eine Antwort würde ich mich sehr freuen.
Liebe Grüße, Annabel
Hallo Annabel,
wenn du beta0 weglässt, setzt du die Konstante quasi fest auf 0. Wenn alle anderen Faktoren also 0 sind, muss die abhängige Variable auch 0 sein.
Schöne Grüße
Daniela